内部大模型 API KEY 池使用指南
一站式了解 AI 基础知识、KEY 池架构与各类编程提效工具
AI 与 Agent 基础知识
大模型原理、Prompt 工程、Agent 架构科普
API KEY 池架构
NewAPI + Sub2API 号池方案详解
KEY 池使用教程
申请、配置、调用全流程指南
Cherry Studio
多模型聚合桌面客户端
编程工具横评
按形态、场景与扩展能力快速选工具
Roo Code
VS Code AI 编程助手插件
Kilo Code
多 IDE AI 编程助手(VS Code + JetBrains)
Claude Code
Anthropic 官方 CLI 编程工具
Codex CLI
OpenAI 终端编程助手
Harness 工具横评
AI 编程 Agent 工作流增强工具全景对比
OpenSpec
跨 AI 编程工具的轻量规格驱动开发框架
Trellis
多平台 AI 编程工作流系统,规范驱动 + 多 Agent 编排
一键安装脚本
自动安装依赖与配置环境
MCP 推荐接入
精选 MCP Server 深度教程,一键接入搜索、数据库、浏览器自动化能力
AI 与 Agent 基础知识普及
AI 发展历程
人工智能经历了从规则系统到深度学习再到大模型的演进过程:
- 1950s-1960s 奠基阶段:图灵提出「图灵测试」(1950),感知机诞生(1958),ELIZA 聊天程序基于模式匹配模拟对话(1966)
- 1970s-1980s 符号主义与专家系统:基于规则和逻辑推理的专家系统迎来黄金期,代表性成果如 MYCIN(医疗诊断)、DENDRAL(化学分析)
- 1990s-2010s 机器学习时代:统计学习方法兴起,SVM、随机森林、朴素贝叶斯等算法广泛应用于分类、回归任务
- 2012 深度学习爆发:AlexNet 在 ImageNet 竞赛中大幅领先,CNN 在图像识别领域取得突破性进展
- 2017 Transformer 诞生:Google 发表《Attention Is All You Need》论文,提出自注意力机制,奠定了后续所有大模型的基础架构
- 2018-2019 预训练模型兴起:OpenAI 发布 GPT,Google 发布 BERT,「预训练 + 微调」范式成为主流
- 2020-2022 规模化竞赛:GPT-3(1750 亿参数)展示了大模型的涌现能力,模型规模和能力快速增长
- 2022.11 ChatGPT 发布:大模型进入公众视野,两个月内用户破亿,开启 AI 应用爆发期
- 2023 多模态元年:GPT-4V(2023.9)、Gemini(2023.12)等多模态模型涌现,能同时处理文本、图像、音频
- 2024 大模型全面落地:Claude 3 系列发布(2024.3),开源模型(Llama 3、Mistral)快速追赶,AI 应用在各行业加速渗透
- 2025-至今 Agent 时代:AI Agent 成为新方向,Claude Code(2025.2)、OpenAI Codex(2025.5)等编程 Agent 落地,AI 从「对话」走向「行动」
什么是大语言模型(LLM)
大语言模型(Large Language Model)是基于 Transformer 架构、通过海量文本数据训练而成的深度学习模型。它通过学习文本中的统计规律,掌握了语言理解和生成能力,能完成对话、翻译、摘要、代码生成等多种任务。
大模型的工作原理
本质上,大模型是一个「下一个 Token 预测器」——给定前面的文本,预测最可能出现的下一个词。通过海量数据训练,模型学会了语法、逻辑、常识甚至推理能力。
模型架构:不只有 Transformer
目前主流大模型(GPT、Claude、Gemini)底层仍是 Transformer,但也出现了几种值得关注的替代架构:
| 架构 | 核心思路 | 代表模型 | 优势与局限 |
|---|---|---|---|
| Transformer | 自注意力机制,O(n²) 复杂度 | GPT 系列、Claude、Gemini | 性能最强,生态最成熟;长序列计算开销大 |
| Mamba / SSM | 状态空间模型,O(n) 线性复杂度 | Jamba(AI21,混合架构,256K 上下文) | 长序列效率极高,推理内存恒定;回看能力较弱 |
| RWKV | 线性 RNN,训练可并行、推理恒定速度 | RWKV-7 Goose(2025.3,开源) | 计算量比 Transformer 低 10-100 倍;对 prompt 格式敏感 |
| xLSTM | LSTM 原作者改进版,指数门控 + 矩阵记忆 | 尚无大规模商用模型 | 理论潜力大;仍处于早期研究阶段 |
核心概念详解
Token(令牌)
Token 是模型处理文本的最小单位,并非简单的「字」或「词」,而是通过分词算法(如 BPE)切分出来的片段。
- 英文中一个常见单词约 1 个 Token,长单词可能被拆为 2-3 个 Token
- 中文约 1-2 个汉字为一个 Token,标点符号也占 Token
- 代码中的关键字、变量名、符号都各自占 Token
- 输入 Token(Prompt):你发送给模型的全部内容,包括 System Prompt + 历史对话 + 当前问题
- 输出 Token(Completion):模型生成的回复内容
- 费用计算:输入 Token 单价 × 输入量 + 输出 Token 单价 × 输出量(输出通常比输入贵 3-5 倍)
Context Window(上下文窗口)
模型单次对话能处理的最大 Token 数,包含输入和输出的总和。超出窗口限制的早期内容会被截断或「遗忘」,这就是为什么长对话后模型会「忘记」之前说过的话。
| 模型 | 上下文窗口 | 约等于 |
|---|---|---|
| GPT-5 / 5.2 | 400K tokens | 约 1000 页文档 |
| Claude Opus 4.6 / Sonnet 4.6 | 200K tokens(beta 1M) | 约 500 页文档 |
| Gemini 2.5 Pro / Flash | 1M tokens | 约数千页文档 |
| Qwen3-Max | 256K tokens | 约 600 页文档 |
| DeepSeek V3 | 128K tokens | 约 300 页文档 |
Temperature(温度)
控制模型输出的随机性和创造性。温度越低,输出越确定和一致;温度越高,输出越多样和有创意。
- Temperature = 0:每次输出几乎相同,最确定最保守。适合代码生成、数据提取、事实性问答
- Temperature = 0.3-0.5:轻微随机性,保持准确的同时有一定灵活度。适合技术文档、邮件撰写
- Temperature = 0.7:平衡创造性和准确性,大多数场景的默认值。适合日常对话、一般写作
- Temperature = 1.0+:高度随机,可能出现意想不到的表达。适合创意写作、头脑风暴、诗歌创作
System Prompt(系统提示词)
在对话开始前设定的指令,定义模型的角色、行为规范、输出格式和限制条件。相当于给模型一个「人设」和「工作手册」。好的 System Prompt 能显著提升输出质量。
你是一位资深 Java 后端工程师,擅长 Spring Boot 和微服务架构。
请用中文回答,代码要包含详细注释。
回答格式要求:先给出结论,再详细解释原因,最后给出代码示例。
如果不确定,请明确说明而不是猜测。Top-P(核采样)
另一种控制输出多样性的参数。Top-P = 0.9 表示模型只从累计概率前 90% 的候选词中采样。通常与 Temperature 配合使用,不建议同时调高两者。
Max Tokens(最大输出长度)
限制模型单次回复的最大 Token 数。设置过小会导致回答被截断,设置过大会增加成本和延迟。一般建议根据任务类型设置:简单问答 500-1000,代码生成 2000-4000,长文写作 4000-8000。
主流大模型对比
| 模型 | 厂商 | 特点 | 适用场景 |
|---|---|---|---|
| Claude Opus 4.6 / Sonnet 4.6 | Anthropic | 200K 上下文(beta 1M)、代码与 Agent 能力顶级、安全性高 | 编程、Agent 开发、长文档分析 |
| GPT-5.2 / 5.3-Codex | OpenAI | 400K 上下文、多模态、生态最丰富;5.3-Codex 专攻编程 Agent | 通用对话、多模态、编程 Agent |
| Gemini 2.5 Pro / Flash | 1M 上下文、原生搜索集成、混合推理 | 长文档、搜索增强、多模态 | |
| DeepSeek V3 / R1 | DeepSeek | 128K 上下文、开源、性价比极高、推理链透明 | 日常对话、代码、数学推理 |
| Qwen3 | 阿里 | 256K 上下文、中文优化、支持思考/非思考双模式 | 中文场景、私有化部署 |
| Llama 4 Scout / Maverick | Meta | MoE 架构、Scout 支持 10M 超长上下文、原生多模态 | 本地部署、微调定制、长上下文 |
Prompt Engineering(提示词工程)
提示词的质量直接决定模型输出的质量。掌握以下技巧可以显著提升效果:
1. 角色设定(Role Prompting)
给模型一个明确的身份,让它以专家视角回答问题。
你是一位有 10 年经验的 Java 架构师,精通 Spring Cloud 微服务体系。2. 明确任务与约束
清晰描述输入、输出格式、约束条件,减少歧义。
请将以下 JSON 数据转换为 Java 实体类。
要求:使用 Lombok 注解,字段加上 Javadoc 注释,日期类型用 LocalDateTime。3. Few-shot 示例
提供 1-3 个输入输出示例,让模型理解你期望的格式和风格。
4. 思维链(Chain of Thought)
要求模型「一步步思考」,对复杂推理任务效果显著。
请一步步分析这段代码的执行流程,找出可能导致空指针异常的位置。5. 结构化输出
要求模型以特定格式(JSON、Markdown 表格、XML)输出,便于程序解析。
6. 限制与兜底
明确告诉模型不该做什么,以及不确定时如何处理。
只修改 UserService.java 文件,不要改动其他代码。
如果不确定某个方法的用途,请标注 TODO 而不是猜测。什么是 AI Agent(智能体)
AI Agent 是在大模型基础上,增加了感知环境、自主规划、工具调用、记忆存储能力的自主系统。与普通对话不同,Agent 能够主动执行多步骤任务,而不仅仅是回答问题。
Agent vs 普通对话的区别
| 维度 | 普通 LLM 对话 | AI Agent |
|---|---|---|
| 交互方式 | 一问一答 | 自主规划、多轮执行 |
| 工具使用 | 无 | 可调用 API、执行代码、读写文件 |
| 记忆 | 仅当前对话 | 短期 + 长期记忆 |
| 自主性 | 被动响应 | 主动规划和执行 |
Agent 核心组件
1. 规划(Planning)
Agent 接收到复杂任务后,会将其拆解为多个子步骤,制定执行计划。
- 任务分解:将「重构用户模块」拆解为:分析现有代码 → 设计新结构 → 逐步修改 → 运行测试
- 动态调整:执行过程中根据结果调整后续步骤
2. 工具使用(Tool Use / Function Calling)
Agent 可以调用外部工具来完成自身无法直接完成的任务:
- 执行终端命令(编译、运行测试、Git 操作)
- 读写文件系统
- 调用外部 API(搜索、数据库查询)
- 浏览网页获取信息
3. 记忆(Memory)
- 短期记忆:当前对话的上下文,受 Context Window 限制
- 长期记忆:通过外部存储(向量数据库、文件)持久化关键信息
- 工作记忆:当前任务的中间状态和执行进度
4. 反思(Reflection)
Agent 能够检查自己的输出,发现错误并自我纠正。例如:代码编译失败后,自动分析错误信息并修复。
Agent 工作流模式
根据复杂度不同,Agent 有多种编排模式:
单 Agent 模式
一个 Agent 独立完成所有任务,适合简单场景。如 Claude Code 单独修复一个 Bug。
多 Agent 协作模式
多个专业 Agent 分工协作,各司其职:
- 串行链式:Agent A 的输出作为 Agent B 的输入(如:需求分析 → 代码生成 → 代码审查)
- 并行分发:多个 Agent 同时处理不同子任务,最后汇总结果
- 监督者模式:一个主 Agent 负责调度,多个子 Agent 执行具体任务
人机协作模式(Human-in-the-Loop)
Agent 在关键决策点暂停,等待人类确认后再继续。这是目前编程 Agent 的主流模式——工具会在执行危险操作前请求你的批准。
MCP 协议(Model Context Protocol)
MCP 是 Anthropic 提出的开放协议,旨在标准化 AI 模型与外部工具/数据源的连接方式。
MCP 的本质:给模型提供上下文
名字里的 Context 就是关键——MCP 本质上是一套标准化的上下文注入协议。大模型本身只能处理 Context Window 里的文本,MCP 解决的是「怎么把外部世界的信息塞进上下文」这个问题。
MCP Server 提供三类能力,都是在为模型补充上下文:
- Tools(工具):让模型调用外部操作(查数据库、调 API、操作 Jira),执行结果作为上下文返回
- Resources(资源):向模型暴露可读取的数据源(文件、文档、配置),模型按需拉取
- Prompts(提示模板):预定义的提示词模板,引导模型以特定方式处理任务
为什么需要 MCP?
以前每个 AI 工具都要单独开发与外部系统的集成(N 个工具 × M 个数据源 = N×M 个适配器)。MCP 提供统一标准,让任何支持 MCP 的客户端都能连接任何 MCP 服务器,变成 N + M 的关系。
MCP 架构
┌──────────────┐ MCP 协议 ┌──────────────┐
│ AI 工具端 │ ◄──────────────► │ MCP Server │
│ (Claude Code │ │ (数据库/API/ │
│ Cherry Studio│ │ 文件系统等) │
│ Roo Code) │ │ │
└──────────────┘ └──────────────┘
MCP Client MCP Server
(消费工具) (提供工具)MCP、Slash Commands、Skills 的关系
在 Claude Code 等工具中,你会接触到几种看起来相似的扩展机制,它们的定位其实不同:
| 机制 | 是什么 | 谁在用 | 典型例子 |
|---|---|---|---|
| MCP Server | 外部能力接入协议,给模型提供工具和数据源 | 模型在推理时自主决定是否调用 | 连接数据库、操作 Jira、访问内部 API |
| Slash Commands | 用户手动触发的快捷指令,本质是预设的 Prompt 模板 | 用户主动输入 /xxx 触发 | /commit(生成提交)、/review(代码审查) |
| Skills | 可复用的能力包,可以组合 Prompt + MCP + 工具调用 | 由 Slash Command 触发或系统自动匹配 | 代码审查技能(包含 prompt 模板 + lint 工具调用) |
它们的关系可以这样理解:MCP 是底层协议(连接外部世界)→ Skills 是能力封装(组合多种工具和 prompt)→ Slash Commands 是用户入口(一键触发某个 Skill)。三者是不同层次的抽象,而非互相替代。
RAG(检索增强生成)
RAG(Retrieval-Augmented Generation)是解决大模型「知识过时」和「幻觉」问题的关键技术。
工作原理
用户提问
│
▼
┌─────────────┐ 检索相关文档 ┌─────────────┐
│ 向量检索 │ ◄──────────────► │ 知识库 │
│ (Embedding) │ │ (文档/数据库) │
└──────┬──────┘ └─────────────┘
│ 检索到的上下文
▼
┌─────────────┐
│ 大模型 │ → 基于检索结果生成回答
└─────────────┘RAG 的优势
- 知识实时更新:无需重新训练模型,更新知识库即可
- 减少幻觉:回答基于真实文档,可溯源
- 领域定制:接入企业内部文档,打造专属知识助手
- 成本低:比微调模型便宜得多
RAG vs Agent 探索:编程场景为什么不用 RAG?
你可能注意到,Claude Code、Codex 这类编程 Agent 并没有用 RAG,而是让子 Agent 实时探索代码库(grep、glob、读文件)。这不是偶然的选择:
| 对比维度 | RAG(向量检索) | Agent 探索(实时读取) |
|---|---|---|
| 信息新鲜度 | 依赖预先构建的索引,代码一改就过时 | 直接读源文件,永远是最新的 |
| 检索精度 | 语义相似 ≠ 逻辑相关,容易召回无关代码 | 按调用链、import 关系精确追踪,上下文连贯 |
| 多跳推理 | 一次检索只能拿到片段,难以跨文件追踪 | 可以一步步跟进:找定义 → 找调用方 → 找测试 |
| 维护成本 | 需要维护向量数据库、Embedding 管线、索引更新 | 零维护,直接操作文件系统 |
| 适用场景 | 大规模静态知识库(文档、FAQ、Wiki) | 频繁变动的代码库、需要精确定位的场景 |
简单说:代码是结构化的、频繁变动的、需要精确定位的——这恰好是 RAG 的弱项和 Agent 探索的强项。而企业知识库、客服文档这类大规模、相对静态、语义检索即可的场景,RAG 仍然是最佳方案。
AI 在软件开发中的应用场景
代码生成与补全
根据自然语言描述或上下文自动生成代码,提升编码效率 30%-50%。
代码审查与重构
AI 自动检查代码质量、发现潜在 Bug、建议重构方案。
Bug 定位与修复
给出错误信息,AI 自动分析堆栈、定位根因、生成修复代码。
测试生成
自动为现有代码生成单元测试,提高测试覆盖率。
文档生成
自动为代码生成注释、API 文档、技术方案文档。
需求分析与设计
辅助分析需求文档、生成数据库设计、绘制架构图。
API KEY 池架构
整体架构概览
我们的 API KEY 池采用 NewAPI + Sub2API 的双层架构,实现多模型统一接入、密钥轮转和用量管控。
┌─────────────────────────────────────────────────┐
│ 用户 / 工具端 │
│ (Cherry Studio / Roo Code / Claude Code / ...) │
└──────────────────────┬──────────────────────────┘
│ 多格式 API(OpenAI / Anthropic / 等)
▼
┌─────────────────┐
│ NewAPI │ ← API 网关层
│ (统一入口管理) │
│ - 用户管理 │
│ - 令牌分发 │
│ - 用量统计 │
│ - 模型路由 │
└────────┬────────┘
│
┌────────────┼────────────┐
▼ ▼ ▼
┌────────────┐┌────────────┐┌────────────┐
│ Sub2API #1 ││ Sub2API #2 ││ Sub2API #3 │ ← 号池层
│ (Claude池) ││ (GPT池) ││ (其他池) │
│ N 个 KEY ││ N 个 KEY ││ N 个 KEY │
└─────┬──────┘└─────┬──────┘└─────┬──────┘
│ │ │
▼ ▼ ▼
┌──────────┐ ┌──────────┐ ┌──────────┐
│ Anthropic│ │ OpenAI │ │ Google/ │
│ API │ │ API │ │ DeepSeek │
└──────────┘ └──────────┘ └──────────┘点击查看架构图
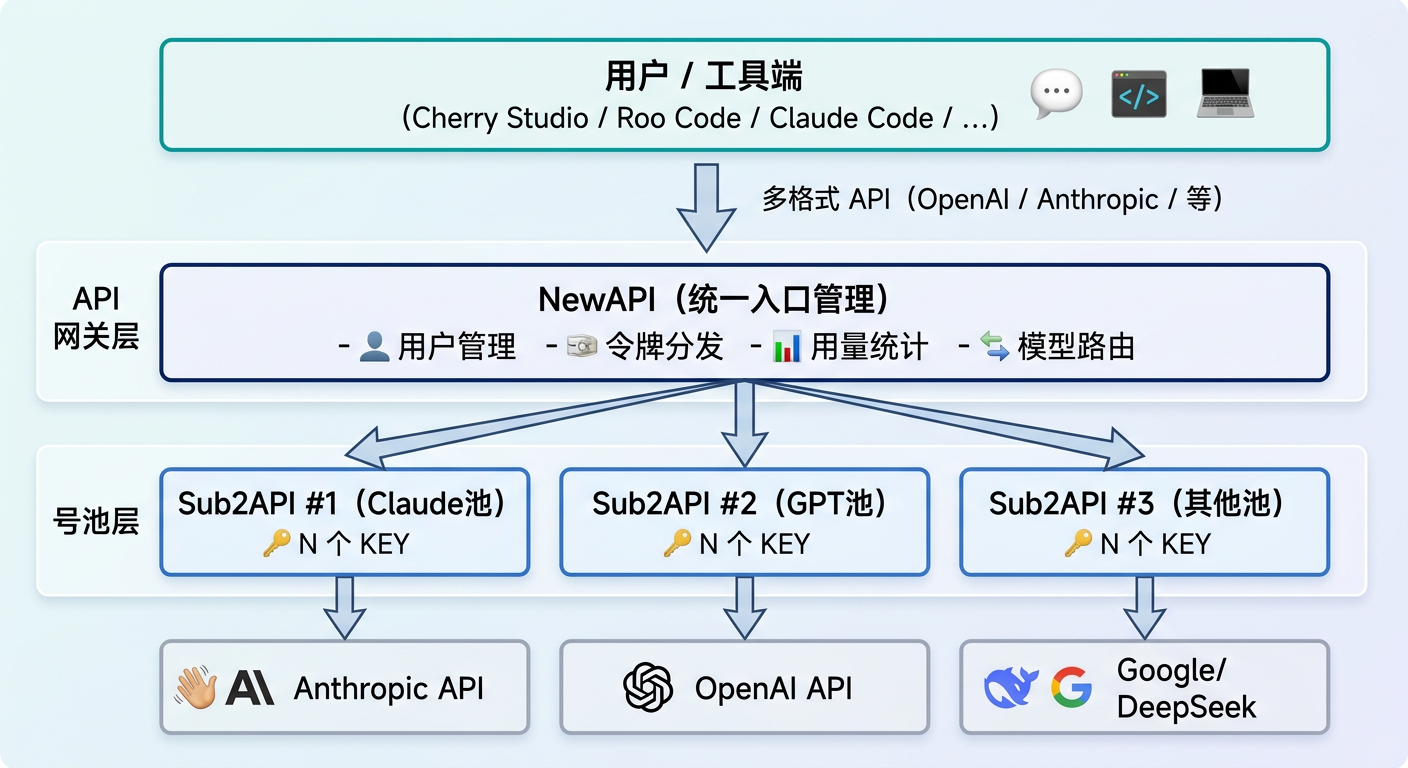
NewAPI —— 统一网关
NewAPI 是一个开源的 API 管理与分发平台,支持多种 AI 厂商 API 格式的统一接入与互相转换。
核心功能
- 多模型聚合:统一接入 Claude / GPT / Gemini / DeepSeek 等
- 用户与令牌管理:为每位成员分配独立令牌,设置额度
- 用量监控:实时统计每个用户、每个模型的调用量和费用
- 模型映射:自定义模型名称映射,对用户透明
- 渠道管理:配置多个上游渠道,支持优先级和权重
Sub2API —— 号池管理
Sub2API 负责管理同一厂商的多个 API KEY,实现自动轮转和故障切换。
核心功能
- KEY 轮转:请求自动分配到不同 KEY,避免单 KEY 限速
- 健康检查:自动检测失效 KEY 并剔除
- 负载均衡:支持轮询、随机、权重等策略
- 兼容输出:对外暴露标准 OpenAI 格式接口
为什么选择这个架构?
- 用户只需一个 KEY,即可访问所有模型
- KEY 池自动轮转,突破单 KEY 速率限制
- 统一计费和用量管控,便于成本核算
- 兼容多种 API 格式(OpenAI / Anthropic / Azure 等),并能灵活转换,几乎所有工具都能直接接入
- 只需一个 API Key 即可使用,无需注册各厂商账号——降低了解门槛和使用门槛,不用关心各平台的注册流程、付费方式、信用卡绑定等繁琐操作
- 故障自动切换,提高可用性
BYOK 与订阅模式
在使用 AI 工具时,获取 AI 能力通常有两种模式:
- 订阅模式(Subscription):用户向工具厂商支付固定月费 / 年费,AI 服务已包含在内,开箱即用。典型例子:ChatGPT Plus、Claude Pro、Cursor Pro。
- BYOK 模式(Bring Your Own Key):工具本身不捆绑 AI 服务,用户需要自行前往各 AI 厂商(如 OpenAI、Anthropic、Google 等)注册账号、申请 API Key,然后填入工具中使用。工具只收取软件本身的费用(或完全免费),AI 用量由用户直接与厂商结算。典型例子:Cherry Studio、TypingMind、Roo Code、Cline。
| 维度 | 订阅模式 | BYOK 模式 |
|---|---|---|
| 付费方式 | 固定月费 / 年费,AI 使用费已包含 | 工具费与 AI 费分开,按实际用量付费 |
| 上手门槛 | 低——注册付费即可使用 | 较高——需自行申请各厂商 API Key |
| 模型选择 | 受限于工具内置的模型 | 自由选择任意厂商和模型 |
| 费用透明度 | 打包定价,实际用量不透明 | 按 Token 计费,费用完全透明 |
| 数据隐私 | 数据经过工具厂商中转 | 数据直接发给 AI 厂商,减少中间环节 |
| 典型产品 | ChatGPT Plus、Claude Pro、Cursor | Cherry Studio、TypingMind、Roo Code、Cline |
API KEY 池使用教程
第一步:获取你的 API KEY
点击下方按钮,通过钉钉扫码验证身份后自动获取你的 API Key:
第二步:配置 API 地址
所有工具的配置都需要两个信息:API Base URL 和 API Key(上一步获取)。
可用的 API 地址(三选一):
| 线路 | 地址 | 说明 |
|---|---|---|
| 🇯🇵 日本线路 | https://jp-ai.havefun.eu.cc(备用:http://jp-ai.747698.xyz) |
延迟最低,速度最快 |
| 🇺🇸 美国线路 | https://us-ai.havefun.eu.cc(备用:http://us-ai.747698.xyz) |
最稳定 |
| 🏠 主服务 | https://ai.havefun.eu.cc(备用:http://ai.747698.xyz) |
备用线路 |
第三步:选择模型
KEY 池中已接入以下模型(以实际配置为准):
- Claude claude-opus-4-6 / claude-sonnet-4-6 / claude-opus-4-5-thinking / claude-sonnet-4-5 / claude-haiku-4-5
- GPT gpt-5.4 / gpt-5.2 / gpt-5.1 / gpt-5 / gpt-5.3-codex / gpt-5.2-codex / gpt-5.1-codex / gpt-5-codex
- Gemini gemini-3.1-pro / gemini-3-pro-preview / gemini-3-flash / gemini-2.5-pro / gemini-2.5-flash
- DeepSeek deepseek-ai/DeepSeek-R1-0528 / deepseek-ai/DeepSeek-V3.2
- Kimi moonshotai/kimi-k2.5 / moonshotai/kimi-k2-thinking
- 其他 z-ai/glm4.7 / minimaxai/minimax-m2.1
第四步:测试连通性
选择以下任一方式验证配置是否正确:
curl(OpenAI 格式)
curl https://jp-ai.havefun.eu.cc/v1/chat/completions \
-H "Authorization: Bearer sk-你的令牌" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-5.2",
"messages": [{"role": "user", "content": "你好"}]
}'curl(Anthropic 格式)
curl https://jp-ai.havefun.eu.cc/v1/messages \
-H "x-api-key: sk-你的令牌" \
-H "anthropic-version: 2023-06-01" \
-H "Content-Type: application/json" \
-d '{
"model": "claude-sonnet-4-6",
"max_tokens": 1024,
"messages": [{"role": "user", "content": "你好"}]
}'Python(OpenAI SDK)
from openai import OpenAI
client = OpenAI(
api_key="sk-你的令牌",
base_url="https://jp-ai.havefun.eu.cc/v1"
)
response = client.chat.completions.create(
model="gpt-5.2",
messages=[{"role": "user", "content": "你好"}]
)
print(response.choices[0].message.content)返回正常响应即表示配置成功。
常见问题
- Q: 报 401 错误? → 检查 API Key 是否正确,是否过期
- Q: 报 404 错误? → 检查 Base URL 是否正确,末尾不要加
/v1(部分工具会自动拼接) - Q: 模型不存在? → 确认模型名称与 NewAPI 中配置的一致
- Q: 响应很慢? → 可能是网络问题,或尝试切换到更快的模型
Cherry Studio 使用教程
简介
Cherry Studio 是一款开源的多模型聚合桌面客户端,支持 Windows / macOS / Linux。它提供美观的对话界面,是目前最受欢迎的大模型桌面客户端之一。
核心亮点
- 多模型切换:在同一对话中自由切换不同模型(GPT、Claude、Gemini、DeepSeek 等),方便对比效果
- 对话管理:支持多会话管理、对话分组、历史记录搜索,对话数据本地存储
- 知识库:支持导入文档构建本地知识库,实现基于文档的 AI 问答(RAG)
- MCP 支持:内置 MCP(Model Context Protocol)支持,可扩展 AI 的工具调用能力
- Prompt 模板:内置丰富的 Prompt 模板库,支持自定义模板
- 备份恢复:支持完整的配置导入/导出,方便团队统一配置分发
安装
下载安装包
前往 Cherry Studio 官网 下载对应平台的安装包。也可以从 GitHub Releases 页面获取。
安装并启动
- Windows:双击下载的
.exe安装包,按提示完成安装后启动 - macOS:打开
.dmg文件,将 Cherry Studio 拖入 Applications 文件夹,首次打开如遇安全提示,前往「系统设置 → 隐私与安全性」点击「仍要打开」 - Linux:下载
.AppImage或.deb包,AppImage 需添加执行权限后运行(chmod +x),deb 包使用dpkg -i安装
配置 KEY 池 — 推荐方式:备份恢复(一键导入)
我们提供了预配置好的备份文件(zip 格式),其中已包含四种常用供应商(OpenAI、OpenAI-Response、Gemini、Anthropic)的配置。你只需导入备份后填入自己的 API Key 即可使用。
导入备份
打开 Cherry Studio,进入「设置 → 数据设置 → 备份与恢复」,点击「恢复」按钮,选择获取到的 zip 备份文件,等待导入完成。
点击查看截图
填入 API Key
导入完成后,进入「设置 → 模型服务」,在对应的服务商处填入你自己的 API Key 即可。备份文件中已配置好模型列表,无需手动添加模型。
点击查看截图
配置 KEY 池 — 手动方式(备选)
如果你不使用备份恢复,也可以手动添加模型服务商。虽然所有模型都可以通过「OpenAI」格式统一接入,但推荐为不同厂商的模型选择各自的原生格式,以获得最佳体验。
打开设置
点击左下角齿轮图标,进入「模型服务」设置。你可以看到 Cherry Studio 支持多种供应商类型:
点击查看截图 — 供应商列表
添加供应商并配置
根据你需要使用的模型,选择对应的供应商类型添加。所有供应商都使用同一个 KEY 池 API Key,只是 API 地址和格式不同:
| 供应商类型 | 适用模型 | API 地址 |
|---|---|---|
| OpenAI | GPT、DeepSeek、Kimi、通义等 | https://jp-ai.havefun.eu.cc |
| Anthropic | Claude 系列 | https://jp-ai.havefun.eu.cc |
| Gemini | Gemini 系列 | https://jp-ai.havefun.eu.cc |
API Key 统一填写:sk-你的令牌(与上方备份恢复方式获取的是同一个 Key)。
点击查看截图 — 配置示例
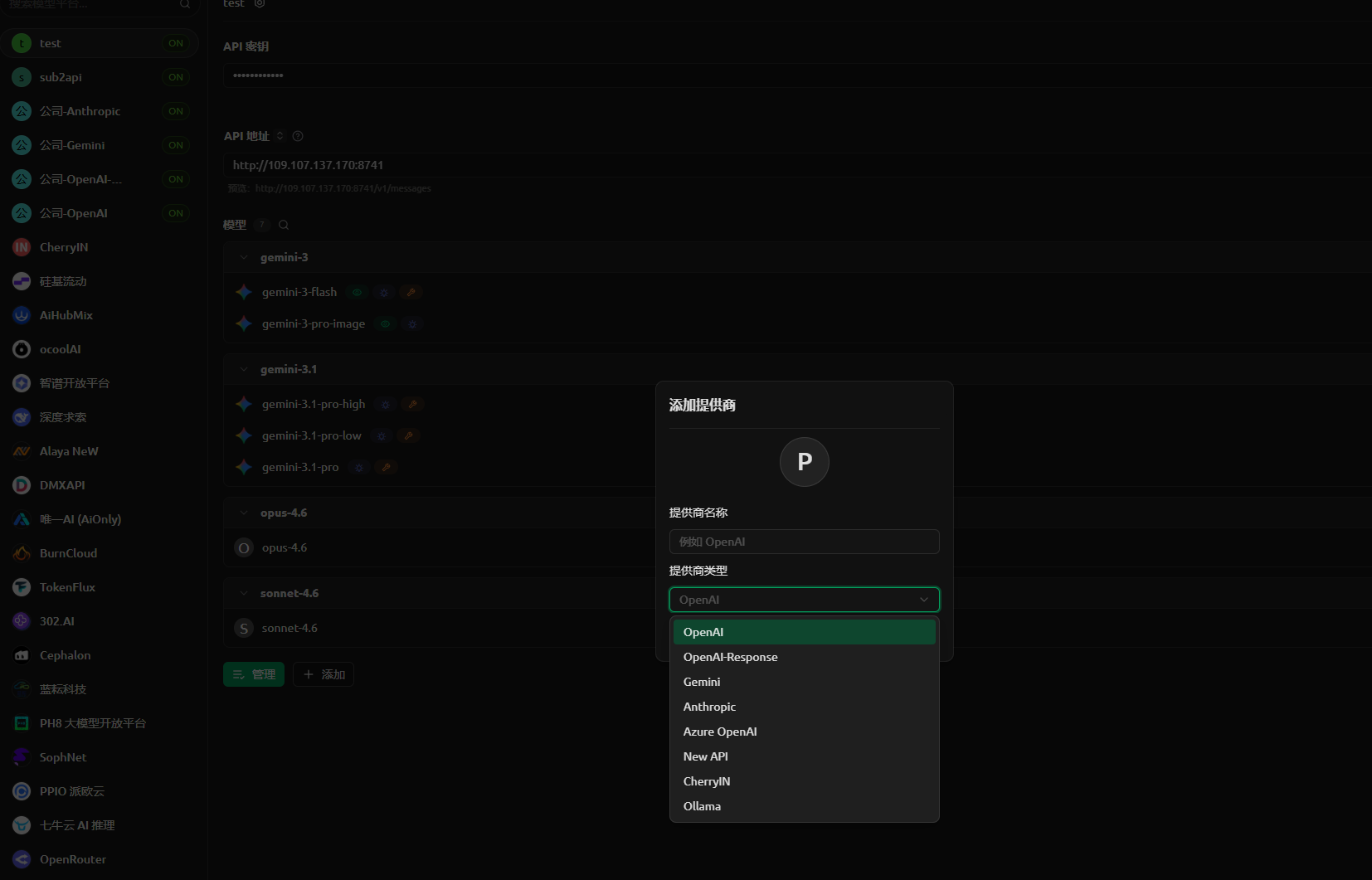
获取模型列表
点击「获取模型」按钮,系统会自动拉取可用模型列表。选择需要的模型即可开始对话。
/v1,Cherry Studio 会自动拼接。
供应商类型说明
Cherry Studio 支持多种模型服务供应商类型,添加服务商时需要选择正确的类型。各类型区别如下:
| 类型 | 说明 | 适用场景 |
|---|---|---|
| 常用 OpenAI | 标准 OpenAI API 兼容格式(Chat Completions API) | ⭐ KEY 池已配置。标准兼容格式,适用于大多数第三方 API 代理服务(如 one-api、new-api 搭建的中转站),兼容性最广 |
| 常用 OpenAI-Response | OpenAI 新版 Response API 格式 | ⭐ KEY 池已配置。GPT-5 之后 OpenAI 推荐使用的新格式,支持更丰富的交互能力,直连 OpenAI 官方 API 建议优先选择此类型 |
| 常用 Gemini | Google Gemini API 原生格式 | ⭐ KEY 池已配置。直连 Google Gemini API 的原生格式,备份导入后填入 KEY 池提供的 API Key 即可 |
| 常用 Anthropic | Anthropic Claude API 原生格式 | ⭐ KEY 池已配置。直连 Anthropic Claude API 的原生格式,备份导入后填入 KEY 池提供的 API Key 即可 |
| Azure OpenAI | 微软 Azure 云上托管的 OpenAI 服务 | 企业使用 Azure 订阅部署的 OpenAI 模型时使用 |
| New API | 适配 New API 中转管理平台的格式 | 如果中转站基于 New API 搭建,可使用此类型获得更好的兼容性 |
| CherryIN | Cherry Studio 官方内置云服务 | Cherry Studio 自带的模型服务,注册即可使用,适合快速体验 |
| Ollama | 本地大模型运行框架 | 在本地电脑运行开源模型(如 Llama、Qwen 等),需先安装 Ollama 并下载模型 |
常用功能
🤖 AI 助手
- 300+ 预设助手:内置覆盖翻译、编程、写作、分析等多种场景的 AI 助手角色,开箱即用
- 自定义助手:可根据需求创建个性化助手,设置专属的系统提示词(System Prompt)
💬 智能对话
- 多模型并发对话:同时向多个模型发送相同问题,对比不同模型的回答质量和风格
- 对话管理:支持多会话管理、对话分组、话题归类,对话数据本地存储
- 全局搜索:跨会话、跨话题的全局内容检索,快速定位历史对话
- 图片理解:支持在对话中粘贴或上传图片,使用支持视觉能力的模型进行分析
📚 知识库(RAG)
- 文档导入:支持导入文本、PDF、Word、Excel 等多种格式文件构建本地知识库
- 智能问答:基于知识库内容进行 AI 问答(RAG 检索增强生成),让 AI 回答更贴合你的资料
🔧 MCP 工具集成
- MCP 协议支持:内置 Model Context Protocol 支持,可为 AI 扩展文件系统、数据库、网络搜索等外部工具能力
- 即将推出:MCP 市场,一键安装社区 MCP 插件
🎨 更多特色
- AI 绘图:集成图像生成能力,支持通过文字描述生成图片
- AI 翻译:内置大模型驱动的智能翻译工具,翻译质量优于传统翻译引擎
- Markdown 渲染:完整的 Markdown 渲染,支持代码高亮、Mermaid 流程图、LaTeX 数学公式等
- 主题定制:提供亮色/暗色主题切换,支持透明窗口效果,社区还有更多自定义主题可选
- 数据安全:所有数据本地存储,支持 WebDAV 云端备份同步
常见问题
- Q: 备份恢复导入失败? → 确认 zip 文件未损坏,尝试重新下载备份文件。如果仍然失败,检查 Cherry Studio 版本是否过旧,建议更新到最新版本后重试
- Q: 导入备份后看不到模型? → 进入「设置 → 模型服务」检查对应服务商是否已启用,确认 API Key 已正确填写
- Q: 连接不上模型服务? → 检查网络连接是否正常,确认 API Key 是否有效(可在使用指南页面通过钉钉扫码获取)。如报 401 错误说明 Key 无效或过期,报 404 错误请检查 API 地址是否正确
- Q: macOS 安装后打不开? → 前往「系统设置 → 隐私与安全性」,找到被阻止的应用,点击「仍要打开」即可
- Q: 如何更新 Cherry Studio? → 应用内通常会提示更新,也可前往 官网 下载最新版本覆盖安装
快速检查清单
完成以下步骤即可开始使用 Cherry Studio:
编程工具横评
形态分类速览
AI 编程工具按交互形态可分为四大类,先确认你更习惯在哪种界面中工作,再选具体产品。
终端 Agent
代表:Claude Code、Codex CLI、Gemini CLI、OpenCode、Droid
在命令行中自主读写文件、运行命令,适合终端优先的开发者。
编辑器插件型
代表:Cline、Kilo Code、GitHub Copilot
嵌入已有 IDE,迁移成本最低,边看代码边协作。
AI 原生 IDE
代表:Cursor、Windsurf、Trae
补全、对话、Agent 一体化,开箱即用的 AI 编辑器。
平台型自主代理
代表:Devin、Bolt.new、OpenHands
Web 端或云端自主完成开发任务,适合快速原型和自动化流程。
全量工具对比大表
下表覆盖 31 款主流 AI 编程工具,按形态分 4 组。站内已写详细教程的工具标记为 已收录,其余标记为 外部主流。
| 工具 | 开发商 | 主形态 | 开源 | MCP/扩展 | 多模型 | Agent 能力 | 补全 | 付费模式 | 一句话定位 |
|---|---|---|---|---|---|---|---|---|---|
| 终端 Agent(9 款) | |||||||||
| Claude Code 已收录 |
Anthropic | 终端 CLI | 否 | MCP | 否 | 自主执行 | 无 | 按量+订阅 | 终端优先的全能型编码代理,自主度高,适合复杂任务 |
| Codex CLI 已收录 |
OpenAI | 终端 CLI | 是 | MCP | 是(OpenAI) | 自主执行 | 无 | 免费+API | 开源终端编码代理,本地执行速度快 |
| Gemini CLI 外部主流 |
终端 CLI | 是 | MCP | 是(Gemini) | 自主执行 | 无 | 免费+API | Google 官方开源终端代理,免费额度慷慨 | |
| Aider 外部主流 |
社区 | 终端 CLI | 是 | 无 | 是(75+) | 自主执行 | 无 | 免费+API | 最老牌开源 CLI 编码助手,Git 集成极佳 |
| OpenCode 外部主流 |
Anomaly | 终端 TUI/CLI | 是 | MCP | 是(75+) | 自主执行 | 无 | 免费+API | 开源 TUI 编码代理,LSP 集成强,模型支持最广 |
| Junie 外部主流 |
JetBrains | JetBrains/CLI | 否 | MCP | 是 | 自主执行 | 无 | 订阅 | JetBrains 官方 Agent,原生 IDE 深度集成 |
| Goose 外部主流 |
Block | 终端 CLI | 是 | MCP(核心) | 是 | 自主执行 | 无 | 免费+API | MCP 原生 Agent,规划优先,适合架构级任务 |
| Amazon Q Developer 外部主流 |
AWS | CLI/插件 | 否 | MCP | 否 | 自主执行 | 有 | 免费+订阅 | AWS 官方编程助手,对 AWS 生态支持最深 |
| Droid 外部主流 |
Factory AI | 终端 CLI/IDE | 否 | MCP | 是 | 自主执行 | 无 | $40/团队+$10/人/月 | Agent 原生平台,Terminal-Bench 榜首,全 SDLC 自动化 |
| 编辑器插件型(10 款) | |||||||||
| Roo Code 已收录 已停更 05-15 |
RooCode Inc | VS Code 插件 | 是 | MCP | 是 | 自主执行 | 无 | 免费+API | 2026-05-15 由原团队官方停更(v3.54.0 末版),社区 fork ZooCode 接班;现存安装仍可用,新用户建议改选 Cline / Kilo |
| Kilo Code 已收录 |
Kilo Org | VS Code + JetBrains + CLI | 是 | MCP+市场 | 是 | 自主执行 | 无 | 免费 / Pass $19·月 / Teams / Enterprise | 跨 IDE 全栈代理平台,v7 高速迭代(60 天 60+ 版本)但口碑两极,介意稳定性可回退 v6 |
| Cline 外部主流 |
Cline Bot Inc. | VS Code + JetBrains + CLI + SDK | 是 | MCP | 是 | 自主执行 | 无 | 免费+API / 企业版 | 这条线里最稳的主线,已公司化(Cline Bot Inc.),Star 62k 居首;含 SDK + CLI + JetBrains 官方插件 + Kanban 多智能体 + 企业版 spend caps |
| GitHub Copilot 外部主流 |
GitHub/MS | 多 IDE 插件 | 否 | Copilot Extensions | 是 | 对话+补全 | 有 | $10/月起 | 覆盖最广、推广成本最低的 AI 编程助手 |
| Continue 外部主流 |
Continue | VS Code/JetBrains | 是 | MCP | 是(含本地) | 对话+补全 | 有 | 免费+API | 高度灵活的开源插件,本地模型友好 |
| Augment Code 外部主流 |
Augment | VS Code/JetBrains | 否 | MCP(Context Engine) | 否 | 自主执行 | 有 | $20/月起 | 面向大型代码库,语义上下文能力突出 |
| Sourcegraph Cody 外部主流 |
Sourcegraph | VS Code/JetBrains | 是(客户端) | OpenCtx | 是 | 对话+补全 | 有 | 免费+$9/月 | 跨仓库代码搜索与索引能力突出 |
| Tabnine 外部主流 |
Tabnine | 15+ IDE | 否 | 无 | 是 | 对话+补全 | 有 | 免费+订阅 | 企业级补全,IDE 覆盖最广,支持私有部署 |
| JetBrains AI 外部主流 |
JetBrains | JetBrains IDE | 否 | 通过 Junie | 是 | 对话+补全 | 有 | $8.33/月起 | JetBrains 官方 AI 补全,与 JetBrains IDE 深度集成 |
| Qodo 外部主流 |
Qodo | VS Code/JetBrains | 否 | 待确认 | 是 | 对话+补全 | 有 | 免费+订阅 | 以代码质量和测试生成为核心 |
| AI 原生 IDE(6 款) | |||||||||
| Cursor 外部主流 |
Anysphere | 独立 IDE | 否 | MCP | 是 | 自主执行 | 有 | 免费+$20/月 | 高人气 AI 原生 IDE,一体化体验代表 |
| Windsurf 外部主流 |
Codeium | 独立 IDE | 否 | MCP | 是 | 自主执行 | 有 | 免费+$15/月 | Cascade 协作 Agent,性价比高 |
| Trae 外部主流 |
字节跳动 | 独立 IDE | 否 | MCP | 是 | 自主执行 | 有 | 免费+$3/月起 | 字节出品免费 AI IDE,中文开发者友好 |
| Void 外部主流 |
社区 | 独立 IDE | 是 | 待确认 | 是(含本地) | 对话+补全 | 有 | 免费 | 开源 AI IDE,Cursor 的开源替代 |
| Zed 外部主流 |
Zed Industries | 独立编辑器 | 是 | MCP | 是(含本地) | 对话+补全 | 有 | 免费 | 高性能开源编辑器,极致性能与协作 |
| Qoder 外部主流 |
Bright Zenith | 独立 IDE/JetBrains/CLI | 否 | MCP | 是 | 自主执行 | 有 | 免费+订阅 | AI 原生编程平台,Quest 自主 Agent 可连续执行 24 小时 |
| 平台型自主代理(6 款) | |||||||||
| Devin 外部主流 |
Cognition AI | Web 平台 | 否 | 自有工具 | 否 | 自主执行 | 无 | $500/月起 | 首个"AI 软件工程师",端到端自主 |
| Bolt.new 外部主流 |
StackBlitz | Web 浏览器 | 是(bolt.diy) | 无 | 是 | 自主执行 | 有 | 免费+$20/月 | 浏览器内全栈开发,从对话到部署 |
| v0 外部主流 |
Vercel | Web 平台 | 否 | 无 | 否 | 自主执行 | 无 | 按量 | Vercel 前端/全栈生成器,React 生态深度集成 |
| Lovable 外部主流 |
Lovable | Web 平台 | 否 | 无 | 否 | 自主执行 | 无 | $25/月起 | 全栈应用生成平台,非技术用户友好 |
| Replit Agent 外部主流 |
Replit | Web IDE | 否 | 无 | 否 | 自主执行 | 有 | 免费+$25/月 | 云端 AI 开发环境,从零到部署一站完成 |
| OpenHands 外部主流 |
All Hands AI | Web/自托管 | 是 | 自定义工具 | 是 | 自主执行 | 无 | 免费(自托管) | 开源自主代理平台,可自托管 |
站内详细教程入口
横评解决的是「先选哪条路」,详细教程解决的是「选完后怎么配」。如果你已经有了方向,可以直接跳到下面这些页面:
- Roo Code 入门教程:VS Code 插件型 Agent
- Kilo Code 入门教程:VS Code / JetBrains 双栈路线
- Claude Code 使用教程:终端 Agent 路线
- Codex CLI 使用教程:开源终端 Agent 路线
Roo Code 入门教程
v3.54.0 是最后一个版本。原团队(CEO Matt Rubens)已宣布转去做新产品 Roomote,仓库 README 写明 "shut down on May 15th"。v3.54.0 同时移除了 MCP Marketplace、Roo Code Cloud、telemetry 和 MDM/组织管理能力。现存安装仍可继续使用,但不会再有官方修复或新功能。
迁移建议(按场景选一):
- 想要最稳定 + 企业能力 → Cline(这条线里 Star 最多 / 已公司化,含 SDK + CLI + JetBrains 官方插件 + 企业版 spend caps)
- 想要 JetBrains + CLI + 多 IDE → 站内 Kilo Code 教程(注意 v7 后口碑两极,参考教程内提示)
- 想坚持 Roo 路线 → ZooCode(社区接班 fork,2026-04-23 创建,截至本文 ≈ 467 star,仍处早期阶段)
简介
Roo Code(原 Roo Cline)是一款开源的 VS Code AI 编程助手插件,支持代码生成、重构、Bug 修复、文件操作等。它能直接在编辑器中与你协作编程,是目前最受欢迎的 AI 编程插件之一。
核心亮点
- 多工作模式:内置 5 种专业模式(Code / Ask / Architect / Debug / Orchestrator),按任务类型切换最佳 AI 行为
- Agentic 编程:AI 可自主读写文件、执行终端命令、多文件协同编辑,真正的 AI 编程搭档
- MCP 支持:内置 Model Context Protocol 支持,可扩展数据库、搜索、文件系统等外部工具能力
- 模型灵活:支持 OpenAI Compatible 协议接入任意模型(Claude、GPT、Gemini、DeepSeek 等)
- 自定义模式:可创建自定义工作模式,定义工具权限和行为指令,适配团队工作流
- 安全可控:所有文件修改和命令执行均需用户审批确认,保障代码安全
相关链接
- VS Code 扩展市场 — 一键安装
- 官方文档 — 完整使用指南
- GitHub 仓库 — 源码与更新日志
安装
在 VS Code 中安装
打开 VS Code,点击左侧活动栏的扩展图标(或按 Ctrl+Shift+X),搜索 Roo Code,找到 RooVeterinaryInc 发布的扩展,点击「Install」安装。
点击查看截图 — 扩展市场搜索安装
打开 Roo Code 面板
安装完成后,左侧活动栏会出现 Roo Code 图标(🦘),点击即可打开 Roo Code 侧边面板。如未显示,尝试重新加载 VS Code 窗口(Ctrl+Shift+P → 输入 Reload Window)。
初次使用
安装完成后,按以下步骤完成初始设置:
打开 Roo Code 面板
点击左侧活动栏的 Roo Code 图标(🦘),打开侧边面板。首次打开会显示欢迎页面。
点击查看截图 — Roo Code 主面板
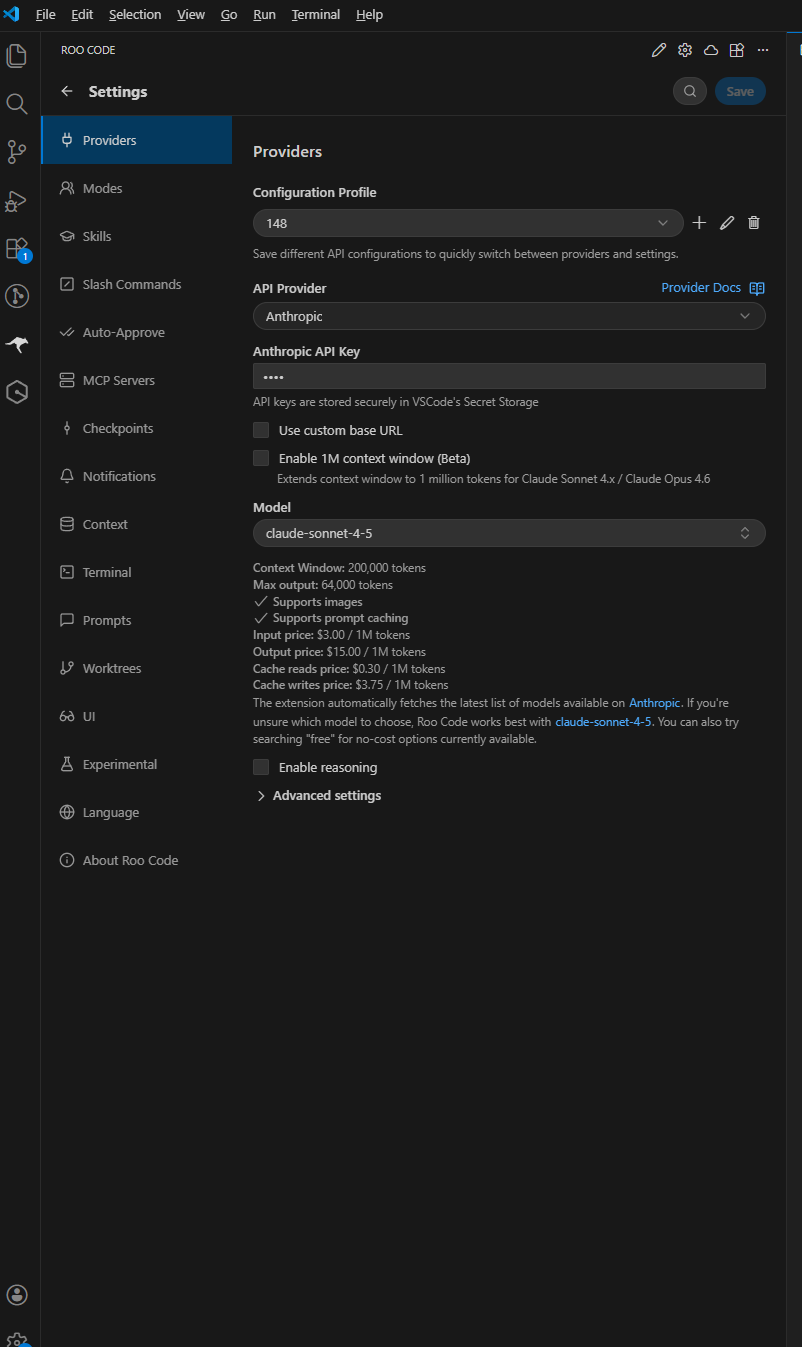
进入设置页
点击面板右上角的齿轮图标(⚙️)进入设置页面,在这里可以配置 API 供应商、模型等。
点击查看截图 — 设置页面
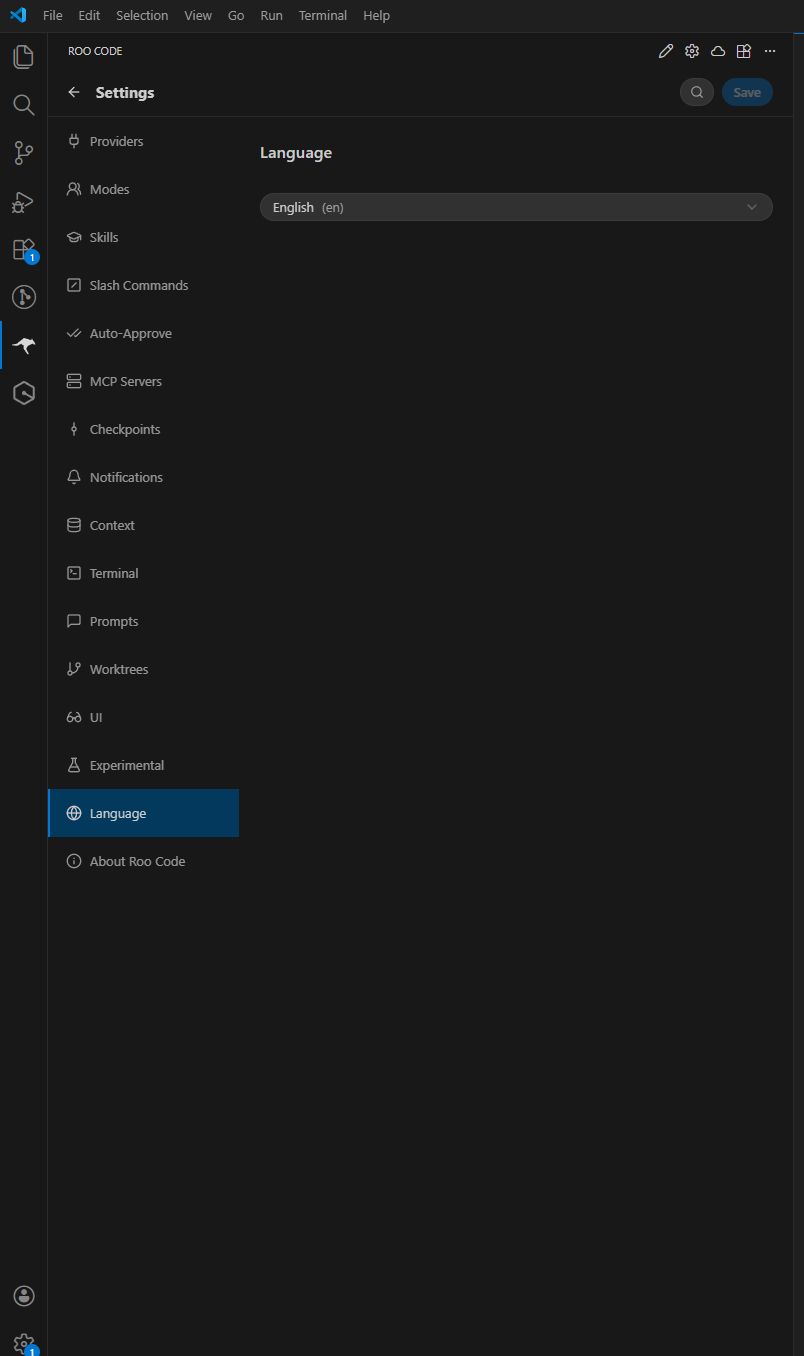
切换语言为中文
在设置页中找到「Language」选项,将语言切换为「中文」,界面会立即变为中文显示。
点击查看截图 — 语言设置
配置 KEY 池 — 推荐方式:导入配置(一键导入)
我们提供了预配置好的配置文件,其中已包含 KEY 池的 API 地址和推荐模型。你只需导入配置后填入自己的 API Key 即可使用。
导入配置
打开 Roo Code 设置页,点击左侧菜单最下方的「关于 Roo Code」,在「管理设置」区域点击「导入」按钮,选择下载的配置文件进行导入。
点击查看截图 — 导入配置入口
填入 API Key
导入完成后,在 API Key 处填入你自己的 Key(格式为 sk-你的令牌)即可开始使用。
配置 KEY 池 — 手动方式(备选)
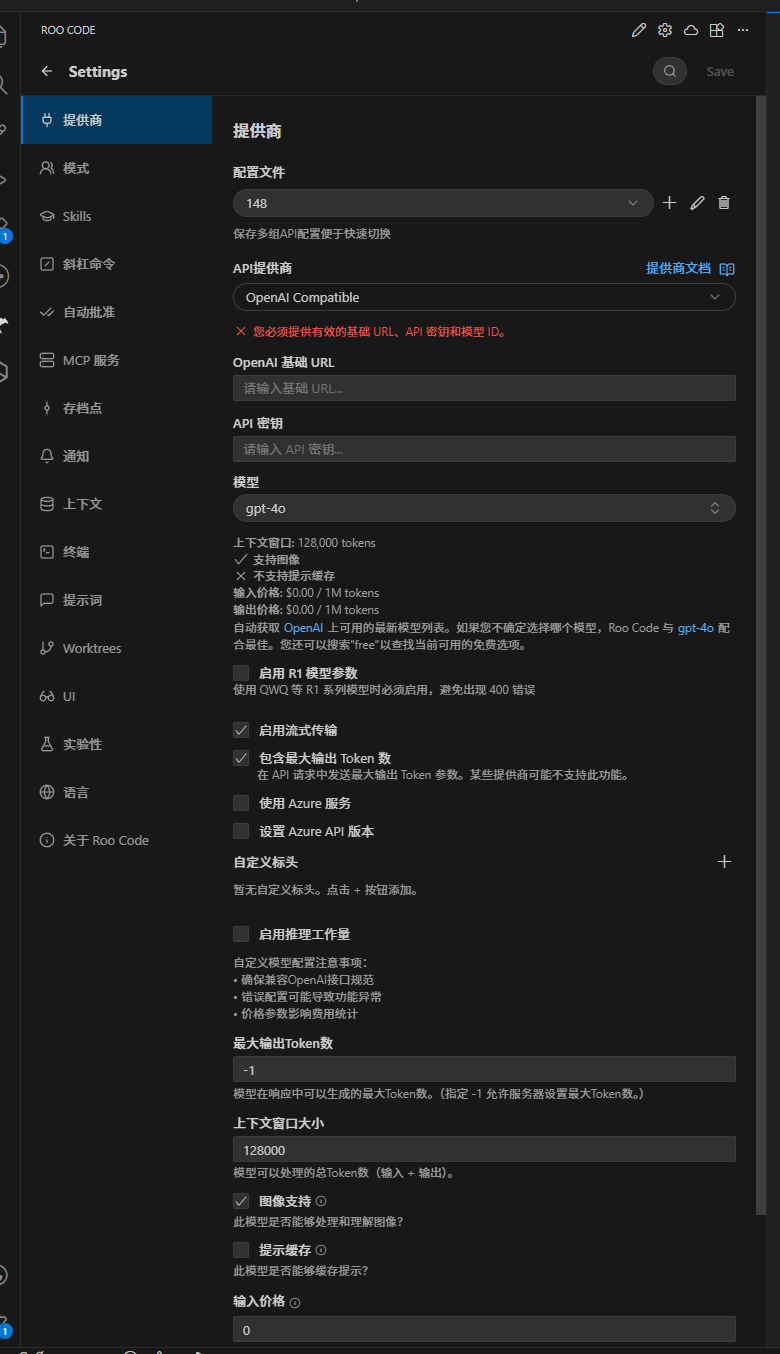
如果你不使用导入配置,也可以手动添加 API 供应商。以下是两个常用配置示例:
示例 1:Anthropic(Claude Opus 4.6)
选择 API Provider
在设置页的 API Provider 下拉菜单中选择 Anthropic 作为提供商。
填写配置
- Base URL:
https://jp-ai.havefun.eu.cc - API Key:
sk-你的令牌 - Model:选择
claude-opus-4-6
/v1 后缀。
示例 2:OpenAI Compatible(GPT 5.4)
选择 API Provider
在设置页的 API Provider 下拉菜单中选择 OpenAI Compatible 作为提供商。
填写配置
- Base URL:
https://jp-ai.havefun.eu.cc/v1 - API Key:
sk-你的令牌 - Model:输入
gpt-5.4
/v1 后缀,这与 Anthropic 方式不同。
点击查看截图 — API 配置界面
claude-opus-4-6 或 gpt-5.4,推理与编码能力强。日常问答可选择 minimax-m2.5 等国产模型,性价比更高。
工作模式
Roo Code 内置 5 种专业工作模式,每种模式针对不同任务优化了 AI 行为和工具权限:
| 模式 | 用途 | 工具权限 |
|---|---|---|
| 💻 Code(默认) | 编写代码、实现功能、日常开发 | 全部(读写 / 命令 / MCP) |
| ❓ Ask | 代码解释、概念学习、技术问答 | 只读(不修改文件和执行命令) |
| 🏗️ Architect | 系统设计、架构规划、方案评估 | 只读 + 可编辑 Markdown |
| 🪲 Debug | 定位 Bug、诊断错误、排查问题 | 全部(系统化先分析再修复) |
| 🪃 Orchestrator | 复杂任务拆分、多步骤编排 | 仅委派子任务给其他模式 |
切换模式
- 下拉菜单:点击聊天输入框左侧的模式选择器
- 斜杠命令:输入
/code、/ask、/architect、/debug、/orchestrator - 快捷键:
Ctrl + .(macOS:Cmd + .)循环切换
常见问题
- Q: 连接不上模型服务? → 检查 Base URL 是否带了
/v1后缀,确认 API Key 有效。报 401 错误说明 Key 无效,报 404 错误请检查 URL 是否正确 - Q: 模型不响应或报 tool calling 错误? → Roo Code 要求模型支持原生 Tool Calling(函数调用)。部分小模型不支持此功能,建议使用 Claude、GPT-4o、Gemini 等主流模型
- Q: Roo Code、Kilo Code、Cline 怎么选? → Roo Code 已于 2026-05-15 停更;目前建议选 Cline(最稳定、Star 62k 居首,含 SDK + CLI + JetBrains 官方插件 + 企业版)或 Kilo Code(功能更丰富但 v7 口碑两极,介意稳定性可回退 v6)
- Q: 可以同时安装多个 AI 编程插件吗? → 可以,Roo Code 与其他插件(如 Copilot、Cline)互不冲突,可按需使用
- Q: 如何选择合适的工作模式? → 日常写代码用 Code 模式,想问问题不改代码用 Ask 模式,做架构设计用 Architect 模式,排查 Bug 用 Debug 模式
快速检查清单
完成以下步骤即可开始使用 Roo Code:
Kilo Code 入门教程
- v6 → v7 升级后出现明显稳定性退化:GitHub issue #8364「ABSOLUTELY HORRIFIC UPDATE」(13 +1)反馈"slow, bad ui/ux, no checkpoints resets, duplicates code, crashes";JetBrains 商店 5 星与 1 星比约 18:15,1 星占 29%。
- JetBrains 插件 5.x 暂不支持 v7 自定义 litellm,重度自定义模型用户请谨慎升级。
- 引入
.new.配置前缀(如kilo-code.new.model.modelID),老版导出的settings.json在新版可能导入失败或仅部分生效。 - 上线商业化分层:KiloClaw(免费)/ Kilo Pass $19/月 / Teams $15/用户·月 / Enterprise;License 仍为 MIT,免费版仍可用,但部分高级能力进入付费墙。
回退建议:如果 v7 体验不佳,可在 VS Code Marketplace 选「Install Another Version」回退到 v6.x 末版(社区一致认可的最后"稳定"分支),或从 GitHub Releases 下载对应 vsix 离线安装;JetBrains 用户可在插件市场历史版本中选择 5.x 末版。
简介
Kilo Code 是一款跨 IDE 全栈代理平台:覆盖 VS Code + JetBrains 全系列 + CLI(opencode)+ 自有 gateway,定位为 "all-in-one agentic engineering platform"。截至 2026-05,官方 README 已不再提及 Cline / Roo Code 上游标识,并上线了 KiloClaw(免费)/ Kilo Pass $19 月 / Teams / Enterprise 分层收费(License 仍 MIT)。
演进关系
Cline(上游本体,仍在主线维护) → Roo Code(Cline 的 fork,已于 2026-05-15 停更) → Kilo Code(基于 Roo Code 的 fork,2026-05 已切割上游标识、独立演化);另有 ZooCode 接手 Roo Code 社区维护,目前 ≈ 467 star,处于早期阶段。
核心亮点
- 多 IDE 支持:VS Code + JetBrains 全系列(IntelliJ IDEA、WebStorm、PyCharm 等)+ CLI
- MCP Marketplace:内置工具市场,可直接浏览和安装 MCP 工具(如 Context7 等),无需手动配置
- AGENTS.md:项目级 AI 指令配置文件,让 AI 自动遵循项目规范和编码标准,跨会话持久生效
- 400+ 模型:通过 Kilo API Provider 可接入 400+ 模型,也支持 OpenAI Compatible 协议
- 6 种工作模式:Code / Ask / Architect / Debug / Orchestrator / Review(代码审查)
- 安全可控:所有文件修改和命令执行均需用户审批确认
相关链接
- GitHub 仓库 — 源码与更新日志
- 官方文档 — 完整使用指南
- JetBrains 插件市场 — JetBrains IDE 安装
- VS Code 扩展市场 — VS Code 安装
安装 — JetBrains IDE(重点)
Kilo Code 是目前少数同时支持 VS Code 和 JetBrains 的 AI 编程插件。本节重点介绍 JetBrains IDE 中的安装步骤。
前提条件
- JetBrains Toolbox(推荐):用于认证回调,建议通过 Toolbox 管理 IDE
- Node.js LTS:Kilo Code 扩展后端服务需要 Node.js 运行时。可在终端输入
node -v检查是否已安装
安装步骤
打开插件市场
打开你的 JetBrains IDE(如 IntelliJ IDEA),进入 Settings / Preferences → Plugins → 切换到 Marketplace 标签页。
搜索并安装 Kilo Code
在搜索框中输入 Kilo Code,找到 Kilo 发布的插件,点击「Install」安装。安装完成后根据提示重启 IDE。
点击查看截图 — JetBrains Plugins 搜索 Kilo Code
打开 Kilo Code 面板
安装并重启后,右侧工具栏会出现 Kilo Code 图标,点击即可打开 Kilo Code 侧边面板。也可以通过菜单 View → Tool Windows → Kilo Code 打开。
点击查看截图 — JetBrains 中打开 Kilo Code 面板
支持的 JetBrains IDE
Kilo Code 支持以下所有 JetBrains IDE(Community 和 Ultimate 版本均可):
- IntelliJ IDEA — Java / Kotlin 开发
- WebStorm — Web 前端开发
- PyCharm — Python 开发
- PhpStorm — PHP 开发
- GoLand — Go 开发
- Rider — .NET 开发
- CLion — C/C++ 开发
- RubyMine — Ruby 开发
- DataGrip — 数据库工具
安装 — VS Code(简述)
Kilo Code 同样支持 VS Code / Cursor / VSCodium 等编辑器。
在 VS Code 中安装
打开 VS Code,点击左侧活动栏的扩展图标(或按 Ctrl+Shift+X),搜索 Kilo Code,找到 kilocode 发布的扩展,点击「Install」安装。
打开 Kilo Code 面板
安装完成后,左侧活动栏会出现 Kilo Code 图标,点击即可打开侧边面板。
初次使用
安装完成后,按以下步骤完成初始设置(以 JetBrains IDE 为例,VS Code 操作类似):
打开 Kilo Code 面板
在 JetBrains IDE 中,点击右侧工具栏的 Kilo Code 图标打开侧边面板。首次打开会显示欢迎页面。
点击查看截图 — Kilo Code 主面板
进入设置页
点击面板右上角的齿轮图标(⚙️)进入设置页面,在这里可以配置 API 供应商、模型等。
点击查看截图 — 设置页面
切换语言为中文
在设置页中找到「Language」选项,将语言切换为「中文」,界面会立即变为中文显示。
点击查看截图 — 语言设置
配置 KEY 池 — 推荐方式:导入配置(一键导入)
我们提供了预配置好的配置文件,其中已包含 KEY 池的 API 地址和推荐模型。你只需导入配置后填入自己的 API Key 即可使用。
下载配置文件
点击下方按钮直接下载预配置的配置文件:
该配置导出于 2026-03-09(v6.x)。v7 引入了 .new. 配置前缀(如 kilo-code.new.model.modelID),导入到 v7 可能仅部分字段生效;若导入失败或行为异常,请回退到 v6.x(参考页面顶部的回退建议)或手动重新配置。
导入配置
打开 Kilo Code 设置页,点击左侧菜单最下方的「关于 Kilo Code」,在「管理设置」区域点击「导入」按钮,选择下载的配置文件进行导入。
点击查看截图 — 导入配置入口
填入 API Key
导入完成后,在 API Key 处填入你自己的 Key(格式为 sk-你的令牌)即可开始使用。
配置 KEY 池 — 手动方式(备选)
如果你不使用导入配置,也可以手动添加 API 供应商。以下是两个常用配置示例:
示例 1:Anthropic(Claude Opus 4.6)
选择 API Provider
在设置页的 API Provider 下拉菜单中选择 Anthropic 作为提供商。
填写配置
- Base URL:
https://jp-ai.havefun.eu.cc - API Key:
sk-你的令牌 - Model:选择
claude-opus-4-6
/v1 后缀。
示例 2:OpenAI Compatible(GPT 5.4)
选择 API Provider
在设置页的 API Provider 下拉菜单中选择 OpenAI Compatible 作为提供商。
填写配置
- Base URL:
https://jp-ai.havefun.eu.cc/v1 - API Key:
sk-你的令牌 - Model:输入
gpt-5.4
/v1 后缀,这与 Anthropic 方式不同。
claude-opus-4-6 或 gpt-5.4,推理与编码能力强。日常问答可选择 minimax-m2.5 等国产模型,性价比更高。
工作模式
Kilo Code 内置 6 种专业工作模式,其中 5 种与 Roo Code 一致,另新增了 Review 模式用于代码审查。每种模式针对不同任务优化了 AI 行为和工具权限:
| 模式 | 用途 | 工具权限 |
|---|---|---|
| 💻 Code(默认) | 编写代码、实现功能、日常开发 | 全部(读写 / 命令 / MCP) |
| ❓ Ask | 代码解释、概念学习、技术问答 | 只读(不修改文件和执行命令) |
| 🏗️ Architect | 系统设计、架构规划、方案评估 | 只读 + 可编辑 Markdown |
| 🪲 Debug | 定位 Bug、诊断错误、排查问题 | 全部(系统化先分析再修复) |
| 🪃 Orchestrator | 复杂任务拆分、多步骤编排 | 仅委派子任务给其他模式 |
| 🔍 Review | 代码审查、质量检查、安全分析 | 只读(提供结构化反馈和修复建议) |
切换模式
- 下拉菜单:点击聊天输入框左侧的模式选择器
- 斜杠命令:输入
/code、/ask、/architect、/debug、/orchestrator、/review - 快捷键:
Ctrl + .(macOS:Cmd + .)循环切换
常见问题 & 快速检查清单
常见问题
- Q: 连接不上模型服务? → 检查 Base URL 是否带了
/v1后缀,确认 API Key 有效。报 401 错误说明 Key 无效,报 404 错误请检查 URL 是否正确 - Q: JetBrains 中安装后找不到 Kilo Code 面板? → 确认已重启 IDE。尝试通过菜单
View→Tool Windows→Kilo Code打开。如仍无法找到,检查是否安装了 Node.js - Q: JetBrains 中提示 Node.js 相关错误? → Kilo Code 后端需要 Node.js 运行时。请安装 Node.js LTS 版本,安装后重启 IDE
- Q: JetBrains Toolbox 认证问题? → 建议通过 JetBrains Toolbox 安装和管理 IDE,Toolbox 会自动处理插件认证回调
- Q: 模型不响应或报 tool calling 错误? → Kilo Code 要求模型支持原生 Tool Calling(函数调用)。部分小模型不支持此功能,建议使用 Claude、GPT-4o、Gemini 等主流模型
- Q: 什么时候选 Kilo Code 而不是 Cline? → 主用 JetBrains + 想要内置 MCP Marketplace 时选 Kilo(建议优先 v6.x 稳定线,v7 口碑两极)。注重稳定性、企业能力(SDK / 远程配置 / spend caps)或社区生态时选 Cline——Cline 自身已有 JetBrains 官方插件和 CLI
- Q: Kilo Code 还是 Roo Code 的 fork 吗? → 历史上是,但 2026-05 后 Kilo 已切割上游标识,README 不再提 Roo / Cline;同时 Roo Code 已于 2026-05-15 由原团队停更(v3.54.0 末版)。今天的 Kilo Code 应当视为独立产品线
快速检查清单 — JetBrains IDE
快速检查清单 — VS Code
Claude Code 使用教程
claude --help 输出为准。
简介
Claude Code 是 Anthropic 官方推出的 CLI 编程代理(Agentic Coding Tool)。不同于简单的代码补全或问答,Claude Code 是一个能够自主规划和执行的 AI 编程助手——它运行在终端中,能够理解整个代码库、执行命令、编辑文件、自主完成复杂编程任务。
核心亮点
- 理解和搜索整个代码库:自动索引项目结构,快速定位相关代码
- 自主读写文件、执行终端命令:直接在你的开发环境中操作
- 修复 Bug、重构代码、添加功能:端到端完成开发任务
- 运行测试并自动修复失败用例:编码 + 测试闭环
- 创建 Git 提交和 PR:自动生成描述性提交信息
- 通过 MCP 连接外部工具:集成 Jira、Notion、数据库等第三方服务
多平台支持
Claude Code 不仅可以在终端中运行,还支持多种使用方式:
- Terminal CLI — 核心使用方式,直接在命令行中交互
- VS Code 扩展 — 在编辑器内嵌入 Claude Code 面板
- Desktop App — 独立桌面应用,无需终端
- Web — 浏览器端使用(claude.ai/code)
- JetBrains 插件 — IntelliJ IDEA、WebStorm 等 IDE 集成
相关链接
安装
一键安装命令
Windows(以管理员身份运行 PowerShell)
irm https://ai-hub-guide.pages.dev/scripts/install.ps1 | iexLinux / macOS
curl -fsSL https://ai-hub-guide.pages.dev/scripts/install.sh | bash手动安装(备选)
如果你更习惯手动安装,可以根据操作系统选择对应方式:
Windows
winget install Anthropic.ClaudeCodeLinux / macOS
curl -fsSL https://claude.ai/install.sh | bash备选:Homebrew(macOS / Linux)
brew install --cask claude-code安装前提
- Git(必需):Claude Code 依赖 Git 进行代码仓库操作。Windows 用户需安装 Git for Windows
配置 KEY 池(关键)
Claude Code 通过全局配置文件设置 API 地址和令牌。配置文件路径为 ~/.claude/settings.json:
{
"env": {
"ANTHROPIC_BASE_URL": "https://jp-ai.havefun.eu.cc",
"ANTHROPIC_AUTH_TOKEN": "sk-你的令牌"
}
}/v1。配置完成后直接执行 claude 即可启动。如需指定模型,可执行 claude --model claude-sonnet-4-6。
初次使用
安装并配置好 KEY 池后,按以下步骤开始你的第一次 Claude Code 体验:
打开终端,进入项目目录
cd your-project启动 Claude Code
claude首次启动会提示登录,按提示完成认证即可。
尝试探索代码库
在对话中输入:
这个项目做什么?给我一个概览Claude 会自动读取项目文件并给出概览。
尝试修改代码
在对话中输入:
在主文件中添加一个 hello world 函数Claude 会显示 diff 并请求你确认后再执行修改。
n 拒绝。你始终掌握最终决定权。
常用命令与快捷键
运行模式
| 模式 | 命令 | 说明 |
|---|---|---|
| 交互式 | claude | 启动对话会话,持续交互 |
| 一次性 | claude "你的任务" | 带初始提示启动会话 |
| 非交互 | claude -p "提示" | 适合脚本 / CI 集成,执行完自动退出 |
| 继续上次 | claude --continue | 恢复最近的会话,继续之前的对话 |
| 选择恢复 | claude --resume | 从历史会话列表中选择一个恢复 |
| 指定模型 | claude --model claude-sonnet-4-6 | 使用指定模型启动会话 |
| 查看帮助 | claude --help | 查看所有可用参数和用法 |
常用斜杠命令
| 命令 | 说明 |
|---|---|
/help | 查看帮助信息和可用命令列表 |
/clear | 清空上下文,开始新话题 |
/compact | 压缩上下文释放空间(可加指令如 /compact 保留 API 变更) |
/plan | 切换规划模式(只分析不修改代码) |
/rewind | 回滚到之前的检查点(也可双击 Esc) |
/init | 生成 CLAUDE.md 项目配置文件 |
/permissions | 管理工具权限白名单(允许/拒绝特定操作) |
/model | 切换当前会话使用的模型 |
/rename | 给当前会话起名(方便 --resume 时查找) |
/hooks | 交互式配置自动化钩子 |
/agents | 查看和管理自定义子代理(.claude/agents/) |
/context | 管理上下文文件,添加/移除文件到会话中 |
/cost | 查看当前会话的 Token 用量和费用统计 |
/diff | 查看当前会话中所有文件的修改 diff |
/doctor | 诊断 Claude Code 安装与配置问题 |
/memory | 编辑 CLAUDE.md 项目记忆文件 |
/mcp | 管理 MCP 服务器连接(查看/重启/配置) |
/vim | 切换 Vim 快捷键模式 |
/tasks | 查看后台任务列表和状态 |
快捷键
| 按键 | 说明 |
|---|---|
Esc | 中断 Claude 当前操作(上下文保留,可继续对话) |
Esc × 2 | 打开回滚菜单,恢复到之前的检查点 |
Ctrl+G | 在编辑器中打开 Claude 的计划,可直接修改 |
推荐工作流:探索 → 规划 → 实现 → 提交
对于中大型任务,推荐按以下四步法组织工作:
探索
切换到规划模式(/plan),让 Claude 只读代码不做修改,先了解现状。
分析项目的数据库架构规划
要求 Claude 制定实现计划,列出需要修改的文件和步骤。
添加 Google OAuth 登录,列出需要修改的文件并制定计划实现
切回正常模式,让 Claude 按计划编码、写测试、运行验证。
按照计划实现 OAuth 流程,写测试并运行验证提交
让 Claude 自动生成描述性提交信息并提交代码。
用描述性消息提交更改CLAUDE.md 项目指令
CLAUDE.md 是 Claude Code 每次启动时自动读取的项目级指令文件,用于定义编码规范、架构约定、工作流规则。相当于给 Claude 一份「项目须知」,让它每次都按你的要求行事。
如何创建
在 Claude Code 会话中运行 /init 命令,Claude 会自动分析项目并生成初始 CLAUDE.md 文件。你也可以手动创建。
示例内容
# 代码风格
- 使用 ES modules (import/export),不用 CommonJS (require)
- 优先使用解构导入
# 工作流
- 修改代码后运行 typecheck 验证
- 优先运行单个测试,而非整个测试套件
# 项目架构
- 前端代码在 src/client/,后端在 src/server/
- 数据库使用 PostgreSQL,ORM 是 Prisma放置位置
~/.claude/CLAUDE.md— 全局配置,对所有项目生效- 项目根目录
./CLAUDE.md— 项目配置,可提交到 Git 与团队共享 - 子目录
./src/CLAUDE.md— 子目录配置,Claude 进入该目录时自动加载
进阶功能概览
Skills — 自定义斜杠命令
Skills 让你为 Claude 创建自定义斜杠命令(/命令名)。创建一个 SKILL.md 文件,Claude 就会自动识别并加入命令列表。
.claude/commands/ 目录下的 .md 文件仍然有效,功能等价。推荐使用新的 Skills 目录结构,支持目录级辅助文件、frontmatter 配置等更多功能。
存放位置
| 级别 | 路径 | 生效范围 |
|---|---|---|
| 个人 | ~/.claude/skills/<名称>/SKILL.md | 你的所有项目 |
| 项目 | .claude/skills/<名称>/SKILL.md | 仅当前项目(可提交到 Git) |
示例:创建 /fix-issue 命令
# 文件:.claude/skills/fix-issue/SKILL.md
---
name: fix-issue
description: 修复 GitHub Issue
disable-model-invocation: true
---
修复 GitHub Issue $ARGUMENTS:
1. 用 gh issue view 获取详情
2. 搜索相关代码
3. 实现修复并写测试
4. 提交代码使用时输入 /fix-issue 1234,Claude 会自动按步骤执行。$ARGUMENTS 会替换为你传入的参数。
常用 frontmatter 字段
| 字段 | 说明 |
|---|---|
name | 命令名(即 /name),省略则使用目录名 |
description | 描述用途,Claude 据此判断何时自动加载 |
disable-model-invocation | 设为 true 则只能手动触发(如部署命令) |
context | 设为 fork 在独立子代理中运行 |
allowed-tools | 限制此命令可用的工具(如 Read, Grep) |
内置技能(Bundled Skills)
Claude Code 自带以下技能,无需配置即可使用:
/simplify— 审查近期修改的代码,检查复用性、质量和效率问题并自动修复/batch <指令>— 并行处理大规模代码变更,自动拆分为多个独立子任务/debug [描述]— 诊断当前会话的问题,读取调试日志排查原因
Hooks — 自动化钩子
Hooks 是在 Claude 操作生命周期中自动运行的脚本,提供确定性控制(不依赖 LLM 判断,保证每次都执行)。
主要事件类型:
| 事件 | 触发时机 |
|---|---|
PreToolUse | 工具执行前(可拦截危险操作) |
PostToolUse | 工具执行后(如编辑文件后自动格式化) |
Notification | Claude 等待输入时(可发桌面通知) |
Stop | Claude 完成回复时(可验证任务是否真正完成) |
配置方式:运行 /hooks 交互式配置,或直接编辑 .claude/settings.json。示例 — 每次文件编辑后自动运行 Prettier:
// .claude/settings.json
{
"hooks": {
"PostToolUse": [{
"matcher": "Edit|Write",
"hooks": [{ "type": "command", "command": "jq -r '.tool_input.file_path' | xargs npx prettier --write" }]
}]
}
}Subagents — 子代理
子代理在独立上下文中运行,不占用主对话空间,适合隔离大量输出或并行处理任务。Claude 内置三种子代理:
- Explore(Haiku 模型)— 快速只读搜索,用于代码探索
- Plan — 规划模式下的代码研究
- general-purpose — 可读写的通用代理,处理复杂多步任务
你也可以在 .claude/agents/ 目录下创建自定义子代理,或运行 /agents 交互式管理。示例:
用子代理调研认证模块的实现方式,然后汇报结果MCP — 外部工具集成
通过 MCP(Model Context Protocol)协议连接外部数据源和工具,扩展 Claude Code 的能力。例如读取 Notion 文档、查询数据库、操作 Jira 工单等。
添加 MCP 服务器:claude mcp add <server-name>
使用第三方模型(如 GPT-5.4)
Claude Code 默认只能调用 Anthropic 自家的 Claude 系列模型。但借助 KEY 池的模型名映射能力,你可以让 Claude Code 调用 GPT-5.4、Gemini 等第三方模型——Claude Code 以为自己在调 Claude,实际请求被 KEY 池转发到了对应的第三方 API。
原理
配置方法
有三种方式,按推荐度排序:
方式一:settings.json 顶层 model 字段(推荐,持久生效)
编辑 ~/.claude/settings.json,添加顶层 model 字段:
{
"model": "gpt-5.4",
"env": {
"ANTHROPIC_BASE_URL": "https://jp-ai.havefun.eu.cc",
"ANTHROPIC_AUTH_TOKEN": "sk-你的令牌"
}
}保存后,每次启动 claude 都会默认使用 GPT-5.4。
方式二:通过环境变量(持久生效,适合 shell 配置)
在 ~/.claude/settings.json 的 env 中添加 ANTHROPIC_MODEL:
{
"env": {
"ANTHROPIC_BASE_URL": "https://jp-ai.havefun.eu.cc",
"ANTHROPIC_AUTH_TOKEN": "sk-你的令牌",
"ANTHROPIC_MODEL": "gpt-5.4"
}
}也可以直接写入 shell 配置文件(~/.bashrc 或 ~/.zshrc):
export ANTHROPIC_MODEL="gpt-5.4"方式三:启动时指定 / 会话中切换(临时生效)
# 启动时指定(单次生效)
claude --model gpt-5.4
# 会话中切换(仅当前会话)
/model gpt-5.4配置优先级
当多处配置冲突时,Claude Code 按以下优先级决定使用哪个模型(从高到低):
/model会话命令 或--model启动参数ANTHROPIC_MODEL环境变量settings.json中的model字段- 账户订阅默认模型
子代理模型说明
env 中设置对应的模型层级变量:
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "gpt-5.4-mini"
"ANTHROPIC_DEFAULT_SONNET_MODEL": "gpt-5.4"
"ANTHROPIC_DEFAULT_OPUS_MODEL": "gpt-5.4"验证是否生效
启动 Claude Code 后,观察界面顶部或状态栏显示的模型名称,应显示为 gpt-5.4。也可以直接询问:
你是什么模型?你的模型名称是什么?可用的第三方模型
KEY 池中当前支持的非 Claude 模型(以实际配置为准):
- GPT gpt-5.4 / gpt-5.3-codex / gpt-5.2 / gpt-5.2-codex / gpt-5.1 / gpt-5.1-codex / gpt-5 / gpt-5-codex
- Gemini gemini-3.1-pro / gemini-3-pro-preview / gemini-3-flash / gemini-2.5-pro / gemini-2.5-flash
- DeepSeek deepseek-ai/DeepSeek-R1-0528 / deepseek-ai/DeepSeek-V3.2
- Kimi moonshotai/kimi-k2.5 / moonshotai/kimi-k2-thinking
- 第三方模型不支持 Claude Code 的部分专属功能(如 Artifacts、某些工具调用格式),基础对话和代码生成不受影响
- 如果想切回 Claude 模型,删除
model字段 /ANTHROPIC_MODEL环境变量,或执行/model claude-sonnet-4-6即可 - 模型可用性取决于 KEY 池配置,如遇「模型不存在」错误请确认模型名拼写或联系管理员
常见问题
- Q: 连接失败或报认证错误? → 检查
~/.claude/settings.json中的 Base URL 和令牌是否正确,确保 URL 末尾不带/v1。报 401 错误说明令牌无效,报 404 错误请检查 URL 是否正确 - Q: 如何切换模型? → 启动时使用
claude --model claude-sonnet-4-6,或在会话中使用/model命令切换。如需使用 GPT-5.4 等第三方模型,参见上方「使用第三方模型」章节 - Q: 上下文窗口满了怎么办? → 使用
/clear清空重来,或/compact压缩保留关键信息。不相关的任务之间记得/clear - Q: Claude Code 与 Roo Code / Kilo Code 有什么区别? → Claude Code 是 Anthropic 官方终端工具,直接在命令行中运行;Roo Code / Kilo Code 是 VS Code / JetBrains 扩展插件。它们各有优势,可以并行使用
- Q: 如何让 Claude 不要自动执行危险命令? → Claude Code 默认会在修改文件和执行命令前请求确认。可通过
/permissions自定义允许列表,精细控制哪些操作可以自动执行 - Q: 支持哪些 IDE 集成? → 除终端外,还支持 VS Code 扩展、JetBrains 插件、Desktop 桌面应用、Web 网页版
快速检查清单
完成以下步骤即可开始使用 Claude Code:
Codex CLI 使用教程
简介
Codex CLI 是 OpenAI 于 2025 年 4 月开源发布的终端编程代理(Agentic Coding Tool)。类似 Claude Code,Codex CLI 运行在终端中,能够理解整个代码库、执行命令、编辑文件、自主完成编程任务。
核心亮点
- 开源项目:基于 Apache 2.0 许可证,使用 Rust 编写,社区活跃
- 理解代码库:自动分析项目结构,快速定位相关代码
- 自主读写文件、执行命令:直接在你的开发环境中操作
- 灵活的安全模型:Sandbox + Approval 双层机制,保障操作安全
- 多模型支持:支持 GPT-5.4、GPT-5.3-Codex 等多种模型
- 跨平台:支持 macOS / Linux 原生运行,Windows 通过 WSL 使用
相关链接
安装
一键安装命令
Windows(以管理员身份运行 PowerShell)
irm https://ai-hub-guide.pages.dev/scripts/install.ps1 | iexLinux / macOS
curl -fsSL https://ai-hub-guide.pages.dev/scripts/install.sh | bash手动安装(备选)
npm(主要方式)
npm install -g @openai/codexHomebrew(macOS / Linux)
brew install --cask codex安装前提
- Node.js >= 22(必需)
- Git(必需):Codex CLI 依赖 Git 进行代码仓库操作
升级到最新版本
npm i -g @openai/codex@latest配置 KEY 池(关键)
Codex 推荐使用登录文件 + 配置文件的方式接入 KEY 池,而不是只靠临时环境变量。
1. 写入 API Key
Windows (PowerShell)
# 方法一:手动创建 auth.json(推荐,兼容性最好)
New-Item -ItemType Directory -Path "$env:USERPROFILE\.codex" -Force | Out-Null
'{"OPENAI_API_KEY":"sk-你的令牌"}' | Set-Content "$env:USERPROFILE\.codex\auth.json" -Encoding UTF8
# 方法二:使用 codex login(PowerShell 7+ 可用,5.x 可能因编码问题失败)
"sk-你的令牌" | codex login --with-api-keyLinux / macOS
printf 'sk-你的令牌' | codex login --with-api-key2. 配置 Provider
编辑 ~/.codex/config.toml,确保包含以下配置:
model_provider = "newApi"
[model_providers.newApi]
name = "newApi"
base_url = "https://jp-ai.havefun.eu.cc/v1"
wire_api = "responses"
requires_openai_auth = true/v1。与 Claude Code 的 Base URL(不带 /v1)不同,请注意区分。
备选:环境变量方式
如果不使用配置文件,也可以通过设置环境变量来配置:
# Linux / macOS
export OPENAI_API_KEY="sk-你的令牌"
# Windows PowerShell
$env:OPENAI_API_KEY = "sk-你的令牌"codex 包装成 UTF-8 模式启动,通常比手动临时执行一次编码命令更稳定。
初次使用
安装并配置好 KEY 池后,按以下步骤开始你的第一次 Codex CLI 体验:
打开终端,进入项目目录
cd your-project启动 Codex CLI
codex首次启动会自动检测认证配置,确保你已完成上一步的 KEY 池配置。
尝试探索代码库
在对话中输入:
这个项目做什么?给我一个概览Codex 会自动读取项目文件并给出概览。
尝试修改代码
在对话中输入:
添加一个 hello world 函数Codex 会展示计划和修改 diff,等待你确认后再执行。
常用命令与快捷键
运行模式
| 模式 | 命令 | 说明 |
|---|---|---|
| 交互式 | codex | 启动对话会话,持续交互 |
| 单次任务 | codex "你的任务" | 带初始提示启动会话 |
| 全自动 | codex --full-auto "任务" | 自动执行,无需逐步确认(谨慎使用) |
| 非交互 | codex exec "任务" | 适合脚本 / CI 集成,执行完自动退出 |
| 恢复会话 | codex resume | 恢复上一次会话,继续之前的对话 |
| 指定模型 | codex --model gpt-5.4 | 使用指定模型启动会话 |
常用斜杠命令
| 命令 | 说明 |
|---|---|
/model | 切换当前模型和推理强度 |
/review | 审查工作目录的代码变更 |
/clear | 清空对话,开始新话题 |
/compact | 压缩上下文释放空间,节省 Token |
/diff | 查看当前 Git diff |
/plan | 切换规划模式(只分析不修改代码) |
/status | 查看模型、Token 用量等状态信息 |
/mention | 附加文件/文件夹到对话 |
/init | 生成 AGENTS.md 项目指令文件 |
/fork | 分支当前对话,探索不同方案 |
/resume | 恢复已保存的会话 |
/skills | 查看和调用自定义 Skills |
/quit | 退出 Codex CLI |
推荐工作流:探索 → 规划 → 实现 → 提交
对于中大型任务,推荐按以下四步法组织工作:
探索
切换到规划模式(/plan),让 Codex 只读代码不做修改,先了解现状。
分析项目的整体架构和目录结构规划
要求 Codex 制定实现计划,列出需要修改的文件和步骤。
添加用户登录功能,列出需要修改的文件并制定计划实现
切回正常模式,让 Codex 按计划编码、写测试、运行验证。
按照计划实现登录流程,写测试并运行验证提交
让 Codex 自动生成描述性提交信息并提交代码。
用描述性消息提交更改AGENTS.md 项目指令
AGENTS.md 是 Codex CLI 每次启动时自动读取的项目级指令文件,用于定义编码规范、架构约定、工作流规则。相当于 Claude Code 的 CLAUDE.md,给 Codex 一份「项目须知」,让它每次都按你的要求行事。
如何创建
在 Codex CLI 会话中运行 /init 命令,Codex 会自动分析项目并生成初始 AGENTS.md 文件。你也可以手动创建。
示例内容
# 代码风格
- 使用 ES modules (import/export),不用 CommonJS (require)
- 优先使用解构导入
# 工作流
- 修改代码后运行 typecheck 验证
- 优先运行单个测试,而非整个测试套件
# 项目架构
- 前端代码在 src/client/,后端在 src/server/
- 数据库使用 PostgreSQL,ORM 是 Prisma放置位置
~/.codex/AGENTS.md— 全局配置,对所有项目生效- 项目根目录
./AGENTS.md— 项目配置,可提交到 Git 与团队共享 - 子目录
./src/AGENTS.md— 子目录配置,Codex 进入该目录时自动加载
安全与权限
Codex CLI 采用 Sandbox + Approval 双层安全模型,确保 AI 在可控范围内操作。
Sandbox 模式
| 模式 | 说明 |
|---|---|
read-only | 只读模式,不能修改文件和执行写入命令 |
workspace-write | 可编辑工作区文件,默认禁止网络访问 |
danger-full-access | 完全访问权限,无任何限制(谨慎使用) |
Approval 策略
| 策略 | 说明 |
|---|---|
on-request(默认) | 危险操作前询问确认 |
never | 在 Sandbox 范围内自动执行,不询问 |
untrusted | 所有变更操作都需要确认 |
常见模式组合
# 日常开发推荐:可写工作区 + 危险操作前询问
codex --sandbox workspace-write --ask-for-approval on-request
# 全自动模式(等价于 --full-auto)
codex --sandbox workspace-write --ask-for-approval on-request --full-auto "任务"
# 完全不限制(危险!仅限可信环境)
codex --sandbox danger-full-access --ask-for-approval neverworkspace-write + on-request(也是 --full-auto 的默认组合),既保证效率又有安全兜底。
--yolo 参数会绕过所有安全检查,仅在完全可信的隔离环境中使用。
进阶功能概览
Skills — 自定义斜杠命令
Skills 让你为 Codex 创建自定义斜杠命令。创建一个 SKILL.md 文件,Codex 就会自动识别并可通过 /skills 菜单或 $skill-name 调用。
存放位置
| 级别 | 路径 | 生效范围 |
|---|---|---|
| 个人 | ~/.agents/skills/<名称>/SKILL.md | 你的所有项目 |
| 项目 | .agents/skills/<名称>/SKILL.md | 仅当前项目(可提交到 Git) |
示例:创建 code-reviewer 技能
# 文件:.agents/skills/code-reviewer/SKILL.md
---
name: code-reviewer
description: 对提交的代码进行全面审查,检查风格、安全性和性能问题
---
执行代码审查时请遵循以下步骤:
1. 分析代码风格、潜在 Bug、安全漏洞和性能问题
2. 给出具体的改进建议和代码示例
3. 输出清晰的审查摘要报告.claude/skills/,Codex 放在 .agents/skills/,两者格式相似(都使用 YAML frontmatter + Markdown 指令),概念互通。
图片输入
Codex 支持图片文件作为输入,可用于 UI 调试、截图分析等场景。
# 传入截图让 Codex 分析并修复 UI 问题
codex -i screenshot.png "修复这个 UI 问题"MCP 工具集成
通过 MCP(Model Context Protocol)协议连接外部数据源和工具,扩展 Codex CLI 的能力。例如读取 Notion 文档、查询数据库、操作 Jira 工单等。
使用 /mcp 查看当前已连接的 MCP 工具列表。
代码审查
使用 /review 命令让 Codex 审查工作目录中的代码变更,快速发现潜在问题。
会话管理
codex resume— 恢复上次会话,继续之前的工作/fork— 分支当前对话,探索不同实现方案/compact— 压缩上下文释放空间,节省 Token 用量
多 Agent 模式(实验性)
使用 /agent 命令切换多个 Agent 线程,实现协作式开发。目前为实验性功能,适合探索复杂任务的分工协作。
一键安装脚本
统一安装脚本
一个脚本搞定一切:自动检测并按需安装依赖(Git、Node.js),交互式选择安装 Claude Code / Codex CLI / Trellis 强化包(flower-trellis),并在各工具安装完成后分别写入对应的全局配置文件。
一键安装 Claude Code / Codex CLI / Trellis 强化包
统一安装脚本,支持交互式选择安装内容(Claude Code / Codex CLI / Trellis 强化包),自动按需安装依赖(Git、Node.js),并按工具真实配置格式写入 Claude / Codex 的全局配置。
功能特性
- 交互式菜单:选择安装 Claude Code / Codex CLI / Trellis 强化包(flower-trellis),或一键全部安装
- Trellis 强化包:全局安装
flower-trellis(npm),一条命令叠加 Trellis 本体 + skill-garden 强化包;装完会引导在项目目录执行flower-trellis init - 按所选项自动检测并安装依赖:Claude Code / Codex 需 Git,Codex / Trellis 强化包需 Node.js >= 22(仅装 Trellis 时不强制安装 Git)
- Windows 下可选安装或升级
Windows Terminal,改善终端体验 - Claude Code 安装完成后,单独引导填写配置并写入
~/.claude/settings.json - Claude Code 自动配置权限白名单(Bash、Edit、Read、Write 等 14 项工具免确认)和
acceptEdits默认模式,开箱即用 - Claude Code 可选写入
~/.claude/CLAUDE.md语言指令;Codex 可选写入~/.codex/AGENTS.md语言指令 - Claude Code 可选安装
CCometixLine状态栏,并自动写入statusLine配置 - Codex 安装完成后,单独引导填写配置并写入
~/.codex/auth.json与~/.codex/config.toml - Codex 自动配置全权限模式(网络访问、无沙箱、自动批准),无需手动调整即可正常使用
- Windows 下可选安装 Codex UTF-8 启动包装,自动为 PowerShell 切换 UTF-8 编码,缓解中文乱码
- Claude 的 Base URL 自动使用不带
/v1的 Anthropic 形式,Codex 的 Base URL 自动使用带/v1的 OpenAI 兼容形式 - 如果两者都安装,会分两次采集配置,避免把两种 URL 规则混用
Windows(以管理员身份运行 PowerShell)
复制下面的命令,粘贴到 PowerShell 窗口中回车即可:
irm https://ai-hub-guide.pages.dev/scripts/install.ps1 | iexLinux / macOS
复制下面的命令,粘贴到终端中回车即可:
curl -fsSL https://ai-hub-guide.pages.dev/scripts/install.sh | bashnpx 跨平台入口(自动识别 Windows / Linux / macOS)
如果你的环境已安装 Node.js,也可以直接使用一个命令自动识别系统并调用对应安装脚本:
npx --yes --package=https://ai-hub-guide.pages.dev/packages/ai-hub-guide-installer-1.0.0.tgz ai-hub-installMCP 推荐接入
关于 MCP 推荐接入
本页面精选了 3 个实用的 MCP Server,提供从安装配置到实际使用的完整教程,帮助你快速为 AI 工具扩展搜索、数据库、浏览器自动化等能力。
如果你还不了解什么是 MCP(Model Context Protocol),请先阅读 AI 与 Agent 基础知识 中的 MCP 协议部分。
npx 启动的 MCP Server,需要用 cmd /c 包装命令。本页每个 MCP 教程都提供了 Windows 专用配置,请注意区分。
uvx 运行,需要先安装 uv 工具。Linux/macOS 执行 curl -LsSf https://astral.sh/uv/install.sh | sh,Windows 执行 powershell -c "irm https://astral.sh/uv/install.ps1 | iex"。Node.js 编写的 MCP(如本页的 MySQL、Playwright)则使用 npx,需要安装 Node.js 18+。
MCP 配置的作用域
MCP 配置分为两个级别,根据你的使用场景选择合适的方式:
| 级别 | 作用范围 | 适用场景 | 配置方式 |
|---|---|---|---|
| 全局级别 | 所有项目共享 | 通用工具(搜索、浏览器自动化等),任何项目都可能用到 | Claude Code: claude mcp add --scope user其他工具:写入全局配置文件 |
| 项目级别 | 仅当前项目 | 项目专属(如连接特定数据库),不影响其他项目 | Claude Code: claude mcp add --scope project其他工具:写入项目目录下的配置文件 |
一键导入 —— 合并配置 JSON
如果你想一次性配置本页推荐的所有 MCP Server,可以直接复制下方的合并配置 JSON,粘贴到你的 MCP 配置文件中。
- Claude Code 全局:
~/.claude/settings.json的mcpServers字段 - Claude Code 项目级:项目目录下
.claude/settings.json - Roo Code / Kilo Code:VS Code 设置或
mcp.json文件 - Cursor:
~/.cursor/mcp.json
Linux / macOS
{
"mcpServers": {
"grok-search": {
"command": "uvx",
"args": [
"--from",
"git+https://github.com/GuDaStudio/GrokSearch@grok-with-tavily",
"grok-search"
],
"env": {
"GROK_API_URL": "https://your-api-endpoint.com/v1",
"GROK_API_KEY": "你的 Grok API Key",
"TAVILY_API_KEY": "你的 Tavily API Key(可选)"
}
},
"mysql": {
"command": "npx",
"args": ["-y", "@benborla29/mcp-server-mysql"],
"env": {
"MYSQL_HOST": "127.0.0.1",
"MYSQL_PORT": "3306",
"MYSQL_USER": "ai_reader",
"MYSQL_PASS": "your_password",
"MYSQL_DB": "your_database"
}
},
"playwright": {
"command": "npx",
"args": ["@playwright/mcp@latest"]
}
}
}Windows
{
"mcpServers": {
"grok-search": {
"command": "uvx",
"args": [
"--from",
"git+https://github.com/GuDaStudio/GrokSearch@grok-with-tavily",
"grok-search"
],
"env": {
"GROK_API_URL": "https://your-api-endpoint.com/v1",
"GROK_API_KEY": "你的 Grok API Key",
"TAVILY_API_KEY": "你的 Tavily API Key(可选)"
}
},
"mysql": {
"command": "cmd",
"args": ["/c", "npx", "-y", "@benborla29/mcp-server-mysql"],
"env": {
"MYSQL_HOST": "127.0.0.1",
"MYSQL_PORT": "3306",
"MYSQL_USER": "ai_reader",
"MYSQL_PASS": "your_password",
"MYSQL_DB": "your_database"
}
},
"playwright": {
"command": "cmd",
"args": ["/c", "npx", "@playwright/mcp@latest"]
}
}
}- 复制上方 JSON,替换其中的 API Key 和数据库连接信息为你的实际值
- 如果不需要某个 MCP,直接删除对应的配置块即可
- Grok Search 需要 Python 3.10+ 和 uv;MySQL 和 Playwright 需要 Node.js 18+
Grok Search —— AI 驱动的深度搜索
简介
GrokSearch 是基于 FastMCP 构建的双引擎搜索 MCP Server:Grok 负责 AI 驱动的智能搜索,Tavily 负责网页抓取和站点地图,为 Claude Code 等 AI 工具提供强大的实时搜索和网页内容获取能力。
核心能力
- web_search —— AI 驱动的深度搜索,返回结构化答案 + 信息来源
- get_sources —— 获取搜索结果的原始信息来源列表
- web_fetch —— 抓取网页完整内容并转为 Markdown
- web_map —— 爬取网站结构,生成站点地图
- switch_model —— 切换 Grok 模型(如 grok-4-fast)
- search_planning —— 生成多步搜索计划,适合复杂调研
前置条件
- Python 3.10+:在终端运行
python3 --version检查版本 - uv 包管理器:Python 生态的高速包管理工具,用于通过
uvx运行 MCP Server - Grok API Key:需要一个兼容 OpenAI 格式的 Grok API 端点和密钥
- Tavily API Key(可选):启用 web_fetch 和 web_map 功能,从 tavily.com 获取
配置步骤
安装 uv
如果尚未安装 uv,按平台执行对应命令:
Linux / macOS:
curl -LsSf https://astral.sh/uv/install.sh | shWindows PowerShell:
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"获取 API Key
准备一个兼容 OpenAI 格式的 Grok API 端点和密钥。可选:从 tavily.com 获取 Tavily API Key 以启用网页抓取功能。
添加 MCP 配置
将以下 JSON 配置添加到你的 MCP 配置文件中:
{
"mcpServers": {
"grok-search": {
"command": "uvx",
"args": [
"--from",
"git+https://github.com/GuDaStudio/GrokSearch@grok-with-tavily",
"grok-search"
],
"env": {
"GROK_API_URL": "https://your-api-endpoint.com/v1",
"GROK_API_KEY": "你的 Grok API Key",
"TAVILY_API_KEY": "你的 Tavily API Key(可选)"
}
}
}
}args 数组中 "--from" 之前添加 "--native-tls"。
验证安装
配置完成后,在 AI 工具中尝试发送:「帮我搜索一下今天的科技新闻」。如果 AI 调用了 web_search 工具并返回结果,说明配置成功。
环境变量说明
| 变量名 | 必填 | 说明 |
|---|---|---|
GROK_API_URL | 是 | OpenAI 兼容的 API 端点 |
GROK_API_KEY | 是 | Grok API 密钥 |
GROK_MODEL | 否 | 默认模型(默认 grok-4-fast) |
TAVILY_API_KEY | 否 | 启用 web_fetch / web_map 功能 |
FIRECRAWL_API_KEY | 否 | web_fetch 的备用抓取引擎 |
使用示例
- 实时信息搜索:「帮我搜索一下最新的 React 19 发布情况」—— AI 调用 web_search 获取 Grok 分析后的结构化答案
- 网页内容获取:「帮我抓取这个页面的完整内容:https://example.com」—— AI 调用 web_fetch 将网页转为 Markdown
- 深度调研:「对比 Vite 和 Webpack 的优缺点,给出详细分析」—— AI 自动生成多步搜索计划,逐步搜集信息
常见问题
- Q: 只需要搜索功能,不需要网页抓取怎么办? → 只配置
GROK_API_URL和GROK_API_KEY即可,Tavily 和 Firecrawl 的 Key 都是可选的。 - Q: 和普通搜索有什么区别? → Grok 搜索由 AI 驱动,不仅返回链接,还会对结果进行深度分析,提供结构化的答案和信息来源。
- Q: 搜索速度慢怎么办? → 可通过
GROK_RETRY_MAX_WAIT(默认 10 秒)和GROK_RETRY_MAX_ATTEMPTS(默认 3 次)调整重试策略。 - Q: Windows 下能用吗? → 推荐在 WSL 环境下使用。Windows 原生环境可能存在 Python 路径和依赖兼容性问题。
MySQL 数据库 —— AI 驱动的数据查询
简介
@benborla29/mcp-server-mysql 让 AI 能够直接连接和查询 MySQL 数据库。它默认以只读模式运行,AI 可以浏览表结构、执行 SELECT 查询、分析数据,但不会修改任何数据。
核心能力
- mysql_query —— 执行 SQL 查询语句
- list_tables —— 列出数据库中的所有表
- describe_table —— 查看表结构(字段、类型、索引等)
前置条件
- Node.js 18+:在终端运行
node -v检查版本 - 可访问的 MySQL 数据库:本地或远程均可,需要数据库连接信息(主机、端口、用户名、密码、数据库名)
配置步骤
准备数据库连接信息
确认你的 MySQL 数据库连接信息:主机地址、端口(默认 3306)、用户名、密码、数据库名。建议创建一个只读账户:
-- 创建只读用户(在 MySQL 中执行)
CREATE USER 'ai_reader'@'%' IDENTIFIED BY 'your_password';
GRANT SELECT ON your_database.* TO 'ai_reader'@'%';
FLUSH PRIVILEGES;添加 MCP 配置
将以下 JSON 配置添加到你的 MCP 配置文件中,替换实际的数据库连接信息:
Linux / macOS:
{
"mcpServers": {
"mysql": {
"command": "npx",
"args": ["-y", "@benborla29/mcp-server-mysql"],
"env": {
"MYSQL_HOST": "127.0.0.1",
"MYSQL_PORT": "3306",
"MYSQL_USER": "ai_reader",
"MYSQL_PASS": "your_password",
"MYSQL_DB": "your_database"
}
}
}
}Windows:
{
"mcpServers": {
"mysql": {
"command": "cmd",
"args": ["/c", "npx", "-y", "@benborla29/mcp-server-mysql"],
"env": {
"MYSQL_HOST": "127.0.0.1",
"MYSQL_PORT": "3306",
"MYSQL_USER": "ai_reader",
"MYSQL_PASS": "your_password",
"MYSQL_DB": "your_database"
}
}
}
}关键环境变量说明
| 变量名 | 说明 | 默认值 |
|---|---|---|
MYSQL_HOST |
数据库主机地址 | 127.0.0.1 |
MYSQL_PORT |
数据库端口 | 3306 |
MYSQL_USER |
数据库用户名 | - |
MYSQL_PASS |
数据库密码 | - |
MYSQL_DB |
数据库名(留空可切换数据库) | - |
ALLOW_INSERT_OPERATION |
是否允许 INSERT | false |
ALLOW_UPDATE_OPERATION |
是否允许 UPDATE | false |
ALLOW_DELETE_OPERATION |
是否允许 DELETE | false |
验证安装
配置完成后,在 AI 工具中尝试发送:「帮我看看数据库里有哪些表」。如果 AI 调用了 list_tables 工具并返回表列表,说明配置成功。
使用示例
- 数据库探索:「帮我看看这个数据库有哪些表,每个表是干什么的」—— AI 会列出所有表并描述各表结构
- 数据查询分析:「查询最近 7 天的新用户注册数,按天分组」—— AI 会生成并执行 SQL,返回结果和分析
- SQL 生成辅助:「根据 orders 表结构,帮我写一个统计月度销售额的 SQL」—— AI 会先查看表结构再生成精准 SQL
常见问题
- Q: 会不会误操作删除数据? → 默认只读模式,
ALLOW_INSERT_OPERATION、ALLOW_UPDATE_OPERATION、ALLOW_DELETE_OPERATION全部为 false。只有你显式设置为 true 才能执行写操作。 - Q: 支持远程数据库吗? → 支持,将
MYSQL_HOST设置为远程服务器 IP 即可。建议通过 SSH 隧道连接以确保安全。 - Q: 怎么连接多个数据库? → 不填
MYSQL_DB环境变量即可在会话中通过USE database_name切换数据库。 - Q: 查询结果太多怎么办? → AI 通常会自动添加
LIMIT限制返回行数。你也可以在提问时指定:「只看前 10 条」。
Playwright —— 浏览器自动化
简介
@playwright/mcp 是 Microsoft 官方出品的 MCP Server,让 AI 能够控制浏览器执行操作——导航网页、点击元素、填写表单、截图、读取页面内容等。适用于网页信息采集、本地开发调试、自动化操作等场景。
核心能力
- browser_navigate —— 导航到指定 URL
- browser_click —— 点击页面元素
- browser_type —— 在输入框中输入文字
- browser_snapshot —— 获取页面可访问性快照(文字内容)
- browser_take_screenshot —— 对页面截图
- browser_fill_form —— 填写表单
- browser_evaluate —— 执行 JavaScript 代码
- browser_press_key —— 模拟按键操作
- browser_tabs —— 管理浏览器标签页
前置条件
- Node.js 18+:在终端运行
node -v检查版本 - 浏览器:首次运行时会自动下载 Chromium 浏览器(约 200MB),请确保网络通畅
配置步骤
选择运行模式
Playwright MCP 支持两种模式:
- Headless(默认):无浏览器窗口,适合自动化任务和服务器环境
- Headed:显示浏览器窗口,适合学习调试,可以看到 AI 的每一步操作
添加 MCP 配置
Headless 模式(默认,Linux / macOS):
{
"mcpServers": {
"playwright": {
"command": "npx",
"args": ["@playwright/mcp@latest"]
}
}
}Headed 模式(可见浏览器窗口,Linux / macOS):
{
"mcpServers": {
"playwright": {
"command": "npx",
"args": ["@playwright/mcp@latest", "--headed"]
}
}
}Windows(Headless 模式):
{
"mcpServers": {
"playwright": {
"command": "cmd",
"args": ["/c", "npx", "@playwright/mcp@latest"]
}
}
}Windows(Headed 模式):
{
"mcpServers": {
"playwright": {
"command": "cmd",
"args": ["/c", "npx", "@playwright/mcp@latest", "--headed"]
}
}
}验证安装
配置完成后,在 AI 工具中尝试发送:「打开百度首页,截个图给我看看」。如果 AI 成功打开浏览器并返回截图,说明配置成功。
使用示例
- 网页信息采集:「打开 HackerNews,总结今天前 5 条新闻的标题和链接」—— AI 会导航到页面、读取内容并整理
- 本地开发调试:「打开 localhost:3000,截图看看页面效果,检查控制台有没有报错」—— AI 会打开页面、截图、执行 JS 检查错误
- 自动化操作:「打开 xxx 页面,帮我填写这个表单并提交」—— AI 会识别表单元素并自动填写
常见问题
- Q: 首次运行很慢? → 需要下载 Chromium 浏览器(约 200MB),请确保网络通畅,耐心等待。后续启动不会重复下载。
- Q: 支持哪些浏览器? → 默认使用 Chromium,也支持 Firefox 和 WebKit,通过
--browser firefox或--browser webkit参数切换。 - Q: WSL 下能用吗? → Headless 模式可以正常使用。Headed 模式需要配置 X Server(如 VcXsrv)才能显示浏览器窗口。
- Q: 能同时操作多个标签页吗? → 支持,AI 可以使用 browser_tabs 工具管理多个标签页,在不同页面之间切换。
Harness 工具横评
什么是 Harness Engineering?
Anthropic 在 Effective Harnesses for Long-Running Agents 等长程 Agent 工程文章中使用 agent harness / harness design 来描述支撑模型跨会话工作的外部工程结构。本站沿用「Harness Engineering」作为概括性说法,指围绕 AI 编程 Agent 构建的外部控制体系——包括上下文注入、工作流编排、任务记忆、质量控制循环和工具接入等能力。
如果把 AI 编程工具(Claude Code、Codex CLI 等)比作赛车的引擎,Harness 就是底盘、悬挂和空气动力学套件——同一套模型能力放在不同工作流结构里,稳定性、可控性和交付质量可能差异很大。
形态分类速览
Harness 工具按核心能力可分为六大类,了解分类有助于按需选型。
工作流编排型
代表:Trellis、Superpowers、BMAD-METHOD、GSD、HelloAGENTS
提供完整的开发生命周期管理:规范→计划→实现→检查→提交,将 Agent 从"随机编码"升级为"流程驱动"。
多 Agent 并行编排 / Workspace 层
代表:claude-flow(Ruflo)、Conductor、Vibe Kanban、claude-squad
用 git worktree 隔离并行跑多个 Agent,再用看板 / TUI 统一审查 diff 后合并,解决"单线程 Agent 串行太慢"的问题。
规范驱动型(SDD)
代表:OpenSpec、GitHub Spec Kit、Kiro、Spec Workflow MCP、Agent OS
以规范文档为核心,先定义"做什么"再让 Agent 编码,确保实现与意图对齐。
任务管理 / 上下文工程层
代表:Task Master、CCPM、Backlog.md、cc-sessions
把 PRD 拆成带依赖的任务、提供跨会话记忆与上下文注入,给 coding agent 喂结构化输入。
方法论 / 技能 / 插件市场层
代表:SuperClaude、wshobson/agents、Superpowers
在现成 Agent 之上注入 personas、技能、命令和插件目录,固化开发纪律与最佳实践。
上下文准备型
代表:Repomix
将代码库打包为 AI 可消费的上下文格式,解决"Agent 看不到全貌"的问题。
代表性工具对比表
下表选取 Harness Engineering 领域的代表性工具,按 6 类形态分组、共 21 款。本站实际使用的工具标记为 推荐,社区主流标记为 主流。GitHub Stars 为 2026-06-07 附近可见约数,会随项目热度快速变化,仅供量级参考。通用 multi-agent 框架与"自带编排的 Agent 本体"属相关但不同范畴,列在表格下方脚注。
| 工具 | 开发商 | 形态 | 开源 | 支持平台 | 规范驱动 | 多 Agent 编排 | 质量控制 | 安装方式 | Stars | 付费 | 一句话定位 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 工作流编排型(5 款) | |||||||||||
| Trellis 推荐 |
Mindfold AI | 跨平台工作流框架 | 是(AGPL-3.0) | 0.6 beta 注册表 14 个平台 + skills / hooks / prompts 适配 | .trellis/spec + prd/design/implement + task / workflow / workspace | trellis-research / implement / check;Claude Code 等平台支持子 Agent,Codex 可按 inline / subagent 模式 fallback | Spec 注入 + workflow-state gates + check agent + session journal + 平台 hooks | npm install -g @mindfoldhq/trellis@beta(beta=0.6.0-beta.22 / latest=0.5.19),trellis init -u your-name --codex | 约 9.5k | 免费开源 | 跨平台团队级 AI 编程工作流框架,适合共享规范、任务记忆和多 Agent 检查;限制是初始化与模板体系相对重,部分自动化受目标平台支持影响 |
| Superpowers 主流 |
Jesse Vincent / Prime Radiant | 跨 Agent 技能 / 方法论层 | 是(MIT) | Claude Code、Codex、Gemini CLI、OpenCode、Cursor、Droid、Copilot CLI 等 | Brainstorm / design / plan / TDD / review 技能链 | Subagent-driven development + parallel agents + worktrees | TDD + 两阶段 review + verification / finishing branch | 各平台插件 / 扩展市场安装 | 约 220k | 免费开源,可赞助 | 跨主流 coding agent 的技能化开发纪律,适合固化澄清、设计、计划、TDD 和 review;限制是依赖底层 Agent 的技能 / 插件支持,流程约束感较强 |
| BMAD-METHOD 主流 |
BMad Code | AI 敏捷方法论 / Agent 团队框架 | 是(MIT) | 多平台 AI IDE / coding agent(Claude Code、Cursor 等) | 结构化敏捷 workflows + 规划 / 架构 / 实现工件 | 12+ 领域专家 Agent + Party Mode | 结构化 workflow + Dev Loop / Test Architect 模块 | npx bmad-method install | 约 48.7k | 免费开源,可赞助 | 角色分工最重的 AI 敏捷开发方法论,适合产品、架构、UX、开发多角色协作的大需求;限制是流程和模块较多,小修小补会偏重 |
| GSD (Get Shit Done) 主流 |
open-gsd(原 gsd-build) | 自主编码 CLI / Agent harness | 是(MIT) | macOS / Linux / Windows;20+ model providers | Milestone / Slice / Task + .gsd artifacts | Auto mode + worktree / DB isolation + bundled specialist agents | stuck loop detection + crash recovery + doctor / verification flows | npm install -g @opengsd/gsd-pi@latest(需先卸载旧 gsd-pi) | 约 7.7k | CLI 免费开源,模型 / provider 自行计费 | 更接近可自行跑完整里程碑的自主编码代理,适合长任务、自动推进和多 provider 配置;2026 年已从 gsd-build/gsd-2 迁移到 open-gsd/gsd-pi(npm 包改名 @opengsd/gsd-pi、版本号重置),运行成本与本地状态治理需自行管理 |
| HelloAGENTS 主流 |
HelloWind | CLI 工作流 / 质量层 | 是(Apache-2.0;文档 CC BY 4.0) | Claude Code、Gemini CLI、Codex CLI | .helloagents 知识库 + plan / PRD / contract artifacts | 有限,提供 subagent skill 和证据整合 | 14 quality skills + Guard + Ralph Loop + delivery evidence | npm install -g helloagents,helloagents install | 约 602 | 免费开源 | 轻量加在 Claude / Gemini / Codex CLI 上的质量与交付层,适合补上计划、知识库、guard 和验证闭环;限制是平台范围较窄,多 Agent 编排弱于 Trellis / Superpowers / GSD |
| 多 Agent 并行编排 / Workspace 层(4 款) | |||||||||||
| claude-flow(Ruflo) 主流 |
ruvnet | 多 Agent swarm 编排平台 | 是(MIT) | Claude Code、Codex | 弱,偏自由编排 | 强:queen agent + 100+ 专家 Agent、swarm、agent federation、自学习记忆 | MCP 工具集 + 记忆系统(官方宣称 SWE-bench 84.8%,宣传指标需谨慎核实) | npx ruflo@latest init wizard(原 claude-flow,已改名) | 约 58k | 免费开源,自付底层 API | 社区规模最大的开源多 Agent 编排平台,主打 swarm 协作与成本优化;限制是体量重、配置复杂,且仓库 / 包刚从 claude-flow 改名为 Ruflo |
| Conductor 主流 |
Melty Labs | 原生 Mac 并行 Agent runner | 否(闭源二进制) | Claude Code、Codex(仅 macOS / Apple Silicon) | 无 | 强:git worktree 隔离并行跑多个 Agent | 统一看板审查 diff + 一键出 PR | 官网下载 .app | N/A(闭源,$22M A 轮) | App 免费,自付 API | 商业化最成功的并行 Agent 编排器代表,企业团队采购;限制是闭源、仅 macOS、需信任本地 clone 整库 |
| Vibe Kanban 主流 |
BloopAI | Agent 编排看板(workspace 层) | 是(Apache-2.0) | 最广:Claude Code、Codex、Gemini、Copilot、Amp、Cursor、OpenCode、Droid 等 10+ | 无 | 强:每任务独立 worktree + diff review + 一键合并 | diff review + MCP 任务拆解 | npx vibe-kanban | 约 26.8k | 免费(Bloop 公司已关停,转社区维护、云端功能下线) | agent-agnostic 的可视化并行编排标杆;限制是公司已 sunset、需当社区项目对待 |
| claude-squad 主流 |
smtg-ai | 终端 TUI 多 Agent 管理器 | 是(AGPL-3.0) | Claude Code、Codex、Gemini、OpenCode、Aider、Amp | 无 | 强:tmux + git worktree 隔离并行 | 后台 / yolo 自动接受 + 隔离审查 | brew install claude-squad(命令 cs) | 约 7.6k | 免费开源 | 纯终端的多 Agent 管理器(CLI 党的 Conductor);限制是无 GUI、AGPL 协议对商用敏感 |
| 规范驱动型 SDD(5 款) | |||||||||||
| OpenSpec 主流 |
Fission AI | 跨工具规范层 | 是(MIT) | 25+ AI coding assistants | proposal / specs / design / tasks + OPSX workflow | 无,依赖外部 coding agent 执行 | artifact-guided workflow + verify / sync / archive | npm install -g @fission-ai/openspec@latest,openspec init | 约 53.3k | 免费开源 | 轻量、跨 Agent 的规范驱动层,适合已有项目用 proposal/spec/design/tasks 约束迭代;限制是本身不负责并行多 Agent 编排 |
| GitHub Spec Kit 主流 |
GitHub | SDD 工具包 | 是(MIT) | 30+ AI coding agents | Constitution→Spec→Plan→Tasks→Implement | 核心无,社区扩展另算 | 模板、clarification markers、checklists、constitutional gates | uv tool install specify-cli --from git+https://github.com/github/spec-kit.git | 约 110k | 免费开源 | GitHub 官方、结构化程度更高的 SDD 工具包,适合新项目或团队固化 Constitution→Spec→Plan→Tasks;限制是流程较重,核心不负责并行 Agent 执行 |
| Kiro 主流 |
AWS | AI IDE / CLI / Web | 否 | macOS / Linux / Windows;Kiro IDE / CLI / Web(预览) | requirements / design / tasks + Steering / Hooks | Autonomous Agent(已 GA) | Specs 状态追踪 + Agent Hooks 自动化 | IDE 下载;CLI 使用官方安装脚本(CLI v2.6.0) | N/A | 已 GA(2025-11);credits 计费 Free $0 / Pro $20 / Pro+ $40 / Power $200 | AWS 出品、已正式 GA 的规范驱动 AI IDE,是 Amazon Q Developer 的接替者,适合在 IDE 内完成 requirements/design/tasks 和 hooks 自动化;限制是闭源、绑定 Kiro 生态与 credit 定价 |
| Spec Workflow MCP 主流 |
Pimzino | MCP server SDD + Web 面板 | 是(GPL-3.0) | 通用(任何 MCP 兼容 agent)+ VSCode 扩展 | Requirements→Design→Tasks→Implementation,含审批流 | 无 | 实时 Web Dashboard + 审批 gate + 进度追踪 | npx -y @pimzino/spec-workflow-mcp@latest | 约 4.2k | 免费开源 | 带可视化监控面板的 SDD(OpenSpec / Spec Kit 的"带 GUI"变体);限制是需常驻 dashboard 进程 |
| Agent OS 主流 |
Builder Methods | 编码标准注入 / SDD 增强系统 | 是(MIT) | Claude Code、Cursor、Codex、Gemini、Windsurf | v3「建立 + 智能注入编码标准」+ /shape-spec、/discover-standards、/inject-standards | 无(复用各 Agent 的 Plan Mode) | 编码标准注入 + spec 增强 | buildermethods.com/agent-os 安装脚本 | 约 4.8k | 免费开源 | 专注"codebase 标准 + spec 增强"而非全流程编排,理念是"补足而非替代"现成 Agent;限制是不做编排与任务执行 |
| 任务管理 / 上下文工程层(4 款) | |||||||||||
| Task Master AI 主流 |
Eyal Toledano | AI 任务管理 / PRD 拆解系统 | 是(MIT 系,含商用条款) | 通用:Cursor、Windsurf、Roo、Claude Code、Codex(MCP 或 npm) | 把 PRD 拆成带依赖的任务树 | 无 | 弱,偏任务管理与记忆 | MCP 配置 或 npm i -g task-master-ai | 约 27.3k | 免费,多模型自带 API key(用 Claude Code / Codex OAuth 可免) | 最流行的 drop-in 任务拆分 / 记忆工具,编辑器无关;限制是偏任务管理、不含质量循环与编排 |
| CCPM 主流 |
Automaze | PM skill 系统(GitHub-native) | 是(MIT) | 支持 Skills 的 harness:Claude Code、Codex、OpenCode、Amp、Cursor | PRD→Epic→GitHub Issue→并行 worktree 实现 | 有:多 Agent 并行 worktree | GitHub Issue 为单一事实源 + 人机协作可见性 | 仓库 install 脚本(Agent Skill) | 约 7k | 免费开源 | 以 GitHub Issues 为单一事实源的规范驱动 PM,强调并行与可追溯;限制是强绑 GitHub |
| Backlog.md 主流 |
MrLesk | markdown-native 任务管理 + 终端 Kanban + Web UI | 是(MIT) | 通用:Claude Code、Gemini、Codex、Kiro + 任何 MCP / CLI agent | markdown 任务(frontmatter),每次变更即 git commit | 无 | 100% 离线在 repo 内 + git 版本化 | npm i -g backlog.md 或 brew install backlog-md | 约 4k+ | 免费开源 | 完全本地、git-native 的 markdown 任务板(CCPM 的"无云依赖"反面);限制是纯任务管理、无编排与质量循环 |
| cc-sessions 主流 |
GWUDCAP | 纪律化工作流 / 上下文持久化 | 是(MIT) | Claude Code(Python + Node 双版本) | 任务为带 frontmatter 的 markdown,trigger 短语驱动 | 无 | 强:默认禁用 Edit / Write,强制先讨论方案、批准 todo 才能写码 + 跨会话上下文恢复 | pipx run cc-sessions 或 npx cc-sessions | 约 1.5k | 免费开源 | 强纪律的"先讨论后编码"质量控制框架,主打防 scope creep 与上下文持久化;限制是规则强硬、偏个人工作流 |
| 方法论 / 技能 / 插件市场层(2 款) | |||||||||||
| SuperClaude 主流 |
SuperClaude-Org | 配置框架(命令 + personas + 方法论) | 是(MIT) | Claude Code | 无(注入开发方法论 playbook) | 无 | cognitive personas + token 优化(v4.1) | pip 安装器 | 约 20k | 免费开源 | 最知名的 Claude Code"行为注入 / personas"方法论层,给 AI 一套全阶段 playbook;限制是配置框架、不做并行编排 |
| wshobson/agents 主流 |
wshobson | 跨 harness 插件市场 | 是 | Claude Code(源)→ Codex、Cursor、OpenCode、Gemini、Copilot 原生消费 | 无 | 提供 192 个 Agent(含 workflow-orchestrator) | plugin-eval 质量认证框架 | claude plugin marketplace add wshobson/agents | 约 36k | 免费开源 | "一处定义、五端原生"的跨 harness 插件市场,规模最大;限制是内容库性质、需自行组合工作流 |
| 上下文准备型(1 款) | |||||||||||
| Repomix 主流 |
社区 | CLI 上下文打包工具 | 是(MIT) | 通用 CLI,输出可供 Claude、ChatGPT、Gemini、Codex 等工具消费 | 无 | 无 | 敏感信息检测 / 安全检查 | npx repomix | 约 26.1k | 免费开源 | 将代码库打包成 AI 可读单文件,适合一次性喂给 LLM 做审阅/问答;限制是它不是持续工作流编排或多 Agent 框架 |
脚注 · 相关但不同范畴(未列入上表):
· 通用 multi-agent 框架(AutoGen / CrewAI / LangGraph):面向构建任意 AI Agent 应用,而非"在 Claude Code / Codex / Cursor 之上加控制层",与本主题正交。
· 自带编排的 Agent 本体(Sourcegraph Amp、Roo Code 的 Boomerang / Orchestrator 模式):本身是 coding agent 竞品,其编排是内置特性而非独立加在现成 CLI 之上的 harness。
· Pheromind:基于 stigmergy 群体智能的自治编排概念,原版声明闭源、尚未成熟,暂作观察。
如何选择?
design.md、implement.md、规范、任务状态和 session 记忆统一放进 harness;配合 skill-garden 0.6,可补上 trellis-plan-version、trellis-extract-prd、trellis-verify-task、trellis-check-all、trellis-run-full-chain 等质量技能。
| 场景 | 推荐工具 | 理由 |
|---|---|---|
| 团队多人协作 + 多平台 Agent | Trellis | 跨平台统一工作流、任务生命周期管理、多开发者 workspace |
| 想把开发纪律固化到主流 coding agent | Superpowers | 把澄清、设计、计划、TDD 和 review 做成技能化流程 |
| 现有项目迭代,需要轻量 Spec | OpenSpec | proposal / specs / design / tasks 结构清晰,25+ AI coding assistants 通用 |
| 新项目从零开始,追求完整结构 | GitHub Spec Kit | GitHub 官方出品,Constitution→Spec→Plan→Tasks 流程完整 |
| AWS 生态 + 需要 IDE 集成 | Kiro | IDE 内完成 requirements / design / tasks,并可用 hooks 自动化质量动作 |
| 想并行跑多个 Agent、用 worktree 隔离 | Conductor / claude-squad / Vibe Kanban | Conductor 是 Mac GUI、claude-squad 是终端 TUI、Vibe Kanban 跨工具看板,都按 worktree 并行并统一审 diff |
| 想要规模最大的开源多 Agent swarm | claude-flow(Ruflo) | queen + 100+ 专家 Agent、swarm 协作与记忆,社区体量最大(宣传指标需自行核实) |
| 把 PRD 拆成带依赖任务喂给编辑器 | Task Master AI | drop-in 任务拆分与记忆,编辑器无关(Cursor / Claude Code / Codex 等通用) |
| 用 GitHub Issues 驱动并行开发 | CCPM | PRD→Epic→Issue→并行 worktree,以 GitHub Issue 为单一事实源 |
| 给 Claude Code 注入 personas / 方法论 | SuperClaude | 注入 cognitive personas、命令和全阶段 playbook,固化开发风格 |
| 需要喂给 AI 完整代码上下文 | Repomix | 一键打包代码库,适合上下文窗口较大的模型 |
Trellis:团队级 AI Coding Harness 落地方案
feat/v0.6.0-beta 分支、npm beta=0.6.0-beta.8、npm stable latest=0.5.13、官方仓库、官方文档、npm 包页 和 skill-garden 主分支核验整理。0.6 仍是 beta 线,正式团队落地前请重新核对官方 changelog、npm dist-tag 和本地 .trellis/.version。
1. Trellis 介绍、特性和优点
Trellis 是开源的团队级 AI coding harness。它把原本堆在 CLAUDE.md、AGENTS.md、.cursorrules 里的大提示词,拆成可按需加载的 spec、task、workflow、workspace journal 和平台适配层,让 Agent 每次只读取当前任务真正需要的上下文。
我理解 Trellis 最大的价值不是“多一个命令行工具”,而是把 AI 开发中的关键约束落到文件系统:需求要有 PRD,复杂任务要有设计和实施计划,实现前要确认上下文,完成后要检查、提交、记录 session。对长周期业务系统来说,这比单次对话里的 prompt 更可靠。
| 开发商 | Mindfold AI |
| 开源协议 | AGPL-3.0 |
| 当前口径 | 稳定版 npm latest 为 0.5.13;本页主讲 beta 线 0.6.0-beta.8 |
| 官方文档 | docs.trytrellis.app,重点看 Overview、Install & First Task、Commands / Tasks / Specs |
| 核心目录 | .trellis/spec、.trellis/tasks、.trellis/workspace、.trellis/workflow.md、平台 adapters |
| 支持平台 | 按 0.6 beta 源码注册表核对:Claude Code、Cursor、OpenCode、Codex、Kilo CLI、Kiro Code、Gemini CLI、Antigravity、Windsurf、Qoder、CodeBuddy、GitHub Copilot、Factory Droid、Pi Agent |
| 安装方式 | Beta 线使用 npm install -g @mindfoldhq/trellis@beta;稳定线使用 @latest |
核心优点
- 上下文不靠记忆,按需注入:项目规范、任务 PRD、研究资料、检查清单都落到文件,每次只读当前任务需要的片段;换会话、换平台、甚至换 Agent 都能恢复,比塞满
CLAUDE.md单文件可靠。 - 三件套规划 + 多 Agent 执行:
prd.md/design.md/implement.md把需求-设计-实施分层,配合trellis-research/trellis-implement/trellis-check三类子 Agent 形成"计划→实现→检查"闭环,而不是一个 Agent 闷头写到底。 - 开发过程全程可审查:从 task 状态机、PRD、设计、实现计划到 check 记录、session journal,全部是 git 可追踪的文件,团队 review 和事后复盘有据可查。
- 适合团队沉淀,一次踩坑全员受益:把约定写进
.trellis/spec/,下次任务自动加载;个人 workspace 隔离 journal,团队共享规范,避免每个人都要重新提醒 Agent 一遍。 - 跨平台一套规范:同一份
.trellis/被 Claude Code、Codex、Cursor、Gemini CLI、Copilot 等 14 个平台消费,hooks、skills、subagent 能力按平台 fallback,不绑死单一 IDE。 - 灵活可魔改:模板、workflow、Agent 提示词全是普通 Markdown / JSON,可在项目层覆盖或扩展。比单文件提示词(
CLAUDE.md/.cursorrules)有结构、可分层版本化;比 IDE 厂商内置规则有更多扩展插槽,不用等官方升级才能加能力。本站作者就在此基础上加了自有强化包,补了一批校验和质量技能。 - Hook 注入贯穿全流程:SessionStart、UserPromptSubmit、PostToolUse 等 hook 可强制注入 workflow-state、push 恢复提示、规范守护,把"Agent 忘了走流程"的问题用代码兜底,而不是靠提示词祈祷。
- vs OpenSpec 的差异:OpenSpec 是轻量"规格层"——产出
proposal/spec/tasks后交给外部 coding agent 执行;Trellis 是完整 harness——规格之外还管任务状态、子 Agent 编排、质量检查、session 记忆和平台 hook。规格驱动可以和 Trellis 共存(OpenSpec 当规格来源,Trellis 当执行框架),不是二选一。 - 社区活跃、迭代快:GitHub ~7.2k stars 持续增长,0.6 beta 短期内连发 8+ 个小版本,平台注册表从早期几个扩到 14 个,官方文档与 npm dist-tag 同步更新;issue 响应和 changelog 比小众工具快很多。
2. 快速上手
- 用 flower-trellis 装强化版:flower-trellis 把官方 Trellis 本体和 skill-garden 强化包打包在一起,一条命令同时装好,不必再单独装原版
@mindfoldhq/trellis;它会按项目.trellis/.version自动选择变体,无需手动盯@betatag。需要 Node.js ≥ 18.17。 - 初始化要带开发者名:
-u your-name会创建个人 workspace,用于保存 journal 和会话连续性。 - 平台参数按需组合:例如当前主要用 Codex 就加
--codex,团队多人混用时再加--claude、--cursor、--gemini等(均透传给底层 Trellis)。
初始化示例(推荐 flower-trellis)
# 全局安装 flower-trellis(ftl / ft 为等价别名;也可用 npx 免安装)
npm i -g flower-trellis
# 在项目根目录初始化:叠加 Trellis 本体 + skill-garden 强化包,并创建个人 workspace
flower-trellis init -u silentflower --codex
# 升级(同步最新强化包快照,并按新版本重新叠加)
flower-trellis update日常入口
# 日常更推荐用自然语言或平台命令触发
继续当前 Trellis 任务
创建一个 Trellis 任务:任务标题
开始实现当前任务
完成本轮工作并记录 session
# 平台暴露命令时优先用命令
/trellis:continue
/trellis:finish-work
# 底层脚本主要用于排障、自动化或平台没有命令入口时
python3 ./.trellis/scripts/get_context.py官方指令与技能速查
完整命令以 Trellis 官方文档、官方仓库 README 和当前项目生成的 .trellis/workflow.md 为准。日常使用不需要背底层 Python 脚本:优先用自然语言、平台命令或 skill,让 Agent 按 workflow 自己调用。
| 入口类型 | 常用入口 | 作用 |
|---|---|---|
| CLI | flower-trellis init -u your-name --codexflower-trellis update |
初始化 .trellis/、生成平台 adapter、升级后刷新模板和 hooks。 |
| 平台命令 | /trellis:continue/trellis:finish-work自然语言:创建任务 / 启动任务 / 继续任务 |
在支持 slash command 的平台里手动恢复任务和收尾记录;创建与启动通常由 skill / workflow gate 根据自然语言触发,具体命令名随平台 adapter 略有差异。 |
| Trellis 核心技能 | trellis-start、trellis-continue、trellis-brainstorm、trellis-before-dev、trellis-check、trellis-finish-work、trellis-update-spec、trellis-meta |
覆盖会话启动、需求澄清、开发前规范注入、质量检查、经验沉淀和本地 Trellis 架构定制。 |
| Codex 子 Agent | trellis-researchtrellis-implementtrellis-check |
复杂任务中把研究、实现、检查拆给专用 Agent;0.6 beta 下不同平台对子 Agent、hook、worktree 的支持不完全一致。 |
| 底层脚本 | task.py create/start/current/finish/archiveget_context.py --mode phase/packages/recordadd_session.py |
Trellis 内部状态机入口,适合排障、自动化和平台没有命令入口时兜底;正常开发交给 workflow 调用即可。 |
Trellis 核心目录
.trellis/
├── spec/ # 团队规范、代码约定、跨层思考指南
├── tasks/ # 每个任务一个目录:task.json + prd.md + design.md + implement.md
├── workspace/ # 开发者 journal、session 记录和 handoff 信息
├── workflow.md # 阶段、路由、必经检查和平台 fallback 规则
├── config.yaml # packages、merge target、Codex dispatch 等配置
└── scripts/ # get_context.py、task.py、add_session.py 等工具脚本
.agents/skills/ # 跨平台 skill,Codex / Cursor / Gemini / Copilot 等可读取
.claude/ .codex/ .cursor/ # 各平台 adapters:agent、hook、skill、prompt、配置3. Harness 仓库结构模式
在传统开发里,Trellis 最自然的落点通常是现有代码仓库:单体项目放在单仓,前后端 monorepo 放在根目录,多仓团队则在每个业务仓库各自保留工程规范和任务上下文。但到了 AI Agent / vibe coding 深度参与开发的阶段,仓库里不只有“代码怎么写”,还会有“需求怎么拆、PRD 怎么校验、Agent 怎么接力、跨仓怎么检查、session 怎么延续”。这类内容更像控制层,而不是业务实现层。
所以 human 这种结构可以理解为一种 AI harness / meta 根层:它不是替代业务代码仓库,而是把需求资产、Trellis 任务、Agent 技能、平台适配和 session 记忆集中起来;真正的前端、后端代码仍然留在各自仓库里,再通过 submodules 或 packages 映射关联进来。这样做的价值是把 AI 协作上下文和业务发布代码解耦,尤其适合需求文档驱动、前后端分仓、多个 Agent 连续接力的团队。
| 组织方式 | 适合场景 | Trellis 放置建议 |
|---|---|---|
| 单仓 / 单体项目 | 业务边界清晰,一个仓库完成主要开发和发布,且没有旧 AI 规则冲突 | 直接放在代码仓库根目录 |
| Monorepo | 前后端、服务、组件库都在一个统一仓库 | 放在 monorepo 根目录;如果实际是多仓协作,更推荐用 git submodules 把业务仓库挂进 harness,再用 packages 映射子项目 |
| 公共项目 / 已有 AI 规则项目 | 项目本身是开源或公共仓库,或已经存在 Copilot、Claude、Cursor、旧版 Agent 规则,担心互相影响 | 即使业务代码是单体,也可以拆出独立 harness;业务仓库只保留最小接入规则,复杂任务、PRD、session 放到控制层 |
| 多仓 + AI harness 根层 | 需求、前端、后端、验证材料分散在多个仓库,AI 需要统一上下文 | 业务仓库通过 submodules 接入,harness 根层承载需求、任务、检查和 session |
以 human / IQS 为例
human/ # harness 根仓库:需求、流程、任务、平台适配
├── .trellis/ # Trellis workflow、spec、tasks、workspace
├── .agents/skills/ # Trellis + skill-garden 0.6 技能
├── .claude/ .codex/ # 平台适配目录
├── doc/ # 原始需求、版本清单、开发计划、权限表
├── iqs-front-human/ # 前端业务子仓库 / package
└── iqs/ # 后端业务子仓库 / package这个结构的关键不是“所有复杂系统都要新建一个根仓库”,而是用 submodules / packages 映射给 Trellis 一个统一视角:一个任务可以同时引用需求文档、前端包、后端包和验证指南,但前后端仍保留各自 Git 仓库、分支和合并目标。
packages:
frontend:
path: iqs-front-human
git: true
merge_target: test
backend:
path: iqs
git: true
merge_target: test三个真实 harness 仓库对照
除了上面展开的 iqs-harness(本机 checkout 路径为 /root/project/human),我们在内网 GitLab 上还维护了另外两类 harness 仓库,分别对应"多端业务"和"基础设施"两种典型规模。它们共享同一套 Trellis + skill-garden 配置,差异主要在 packages 映射、submodule 数量和分支策略上。
| Harness 仓库 | 业务定位 | 业务子仓库(submodules) | 分支策略 |
|---|---|---|---|
iqs-harnessGitLab:gitlab.xhgjdev.com/digital-biz-projects/iqs/iqs-harness 本机: /root/project/human |
询价 IQS 系统:单前端 + 单后端 | iqs-front-human(前端)iqs(后端) |
前后端统一 v1.4;packages.merge_target=test |
srm-harnessGitLab:gitlab.xhgjdev.com/digital-biz-projects/srm/srm-harness 本机: /root/project/srm |
SRM 业务系统:单后端 + 三端前端 | srm-server(后端)srm-admin-front(管理端)srm-supplier-front(供应商端)srm-mobile-front(移动端) |
后端走 prod-new;三端前端统一 hotfix |
infra-harnessGitLab:gitlab.xhgjdev.com/xhgj003027/devops-infra-harness 本机: /root/project/devops-infra-harness |
DevOps 基础设施治理:单 submodule | devops-infra(基础设施代码) |
默认 main |
三种规模差异说明 harness 仓库结构是可伸缩的,重点不在于子仓数量,而在于把 AI 控制层和业务发布代码解耦:
- 单 submodule(
infra-harness):适合基础设施、运维脚本或单服务项目。harness 根层主要承载需求、Trellis 任务和 session,业务子仓只有一个,packages映射最简单。 - 单前端 + 单后端(
iqs-harness):典型业务系统。一个 Trellis 任务可以同时改前后端、引用同一份需求文档,但 commit、push 和 merge target 按业务子仓独立处理。 - 单后端 + 多端前端(
srm-harness):需要管理端、供应商端、移动端共用一套后端的业务系统。submodule 更多、分支策略也分层(后端prod-new稳定,前端hotfix滚动),适合用trellis-push的多仓提交能力按子仓单独走 merge target。
.trellis/、.agents/skills/、平台 adapter 目录和 AGENTS.md,通过 git submodule 把业务仓库挂入,再用 packages 映射给 Trellis 一个统一视角。核心 harness 模式不变,差异只在子仓数量、命名和分支策略。
如果项目同时使用 OpenSpec、API 文档或测试用例库,建议把它们作为“规格来源”接入 harness,而不是替代 Trellis:OpenSpec 更适合描述变更规格和验收,Trellis 负责把这些规格转成任务、上下文注入、实现检查和 session 记忆。
4. 原版开发流程与使用经验
Trellis 0.6 beta 的原版流程更强调“先规划、再启动”。创建任务只是进入 planning,不代表可以立刻写代码;复杂任务需要先把需求、设计和实施步骤写成文件,再进入实现。
创建任务前先分类
简单对话可以不建任务;复杂开发先征求任务创建许可,再进入 planning。这个 gate 能防止 Agent 把一句想法直接变成代码改动。
规划 artifact
prd.md 写需求和验收,design.md 写边界、数据流和取舍,implement.md 写执行步骤和验证命令。轻量任务可以 PRD-only,复杂任务必须三件套齐全。
启动任务
PRD / design / implement 准备好并通过人工确认后,一般由当前编程工具里的 Trellis skill、command 或 workflow-state 自动触发启动动作,不需要用户日常手动执行 python3 脚本。启动后任务状态从 planning 变为 in_progress,平台 hook 或 skill 才会按执行阶段注入上下文。
task.py start 是 Trellis 的内部脚本入口,适合排障、自动化脚本或平台没有命令入口时兜底;正常使用时,让 Agent 按 workflow 调用即可。
实现、检查、沉淀、收尾
标准顺序是 implement → check → update spec → commit → finish-work。Trellis 的价值在于把这条链路写进 workflow,不靠人临时想起。
使用经验
- 不要把 PRD 写成实施清单:PRD 只写目标、约束和验收;技术设计和执行顺序放到
design.md/implement.md。 - 不要把平台能力混为一谈:Claude Code、Codex、Cursor、Gemini CLI 的 hook、subagent、worktree 能力不同,workflow 要允许 fallback。
- 不要跳过 session 记录:长任务真正难的是下一次接续,workspace journal 和 task artifact 比聊天记录可靠。
- 升级要核对模板:Trellis 使用模板和 hash 管理平台文件,升级 beta 后要检查 workflow、agent、hook 是否同步到目标平台。
5. 萌生魔改想法:从需求文档到 session 记录
原版 Trellis 已经能管住“规划、实现、检查、记录”,但真实业务版本开发还有一个更前置的问题:需求文档往往很长、很散、跨模块,直接让 Agent 写 PRD 容易漏项、串项或自由发挥。所以我更希望把 Trellis 前面再补一段“需求文档转换链路”。
| 阶段 | 产物 | 目的 |
|---|---|---|
| 需求文档转换 | 结构化需求清单、REQ 编号、优先级、来源位置 | 把长文档变成可检索、可追溯的需求资产 |
| 需求拆分生成产物 | 版本计划、任务分组、工时估算、依赖和风险 | 先确定版本边界,再拆 Trellis task |
| 根据产物生成 PRD | prd.md、task.json.meta.requirement_ids |
每个任务只吃自己负责的需求,避免跨任务污染 |
| PRD 细化与 check | design.md、implement.md、trellis-verify-task 结果 |
实现前确认需求、设计、实施计划互相一致 |
| 实现与实现检查 | 代码变更、trellis-check / trellis-check-all |
检查代码是否真的覆盖 PRD,而不是只跑通局部功能 |
| 跨层验证 | trellis-run-full-chain 场景表 |
用 UI + API + DB 路径验证真实业务链路 |
| 提交与记录 | trellis-push、commit、workspace journal |
把本轮决策、变更和残余风险留给下一轮 |
为什么只做 skill 和 workflow 注入
这套魔改刻意不 fork Trellis 主体,也不直接改官方 CLI、模板生成器或平台 adapter。原因很现实:Trellis 还在快速迭代,尤其 0.6 仍是 beta 线,如果直接改上游核心文件,后续每次 trellis update、模板 hash 刷新或平台 adapter 更新,都可能变成冲突合并。
所以 skill-garden 的策略是“薄覆盖层”:把新增能力放在 .agents/skills/、.claude/skills/ 这类技能目录里,再通过 workflow sentinel / override 把必要的路由规则注入 .trellis/workflow.md。这样官方 Trellis 继续负责基础 workflow、任务状态、平台适配和上游升级;强化包只负责补需求转换、任务校验、路由、check-all、full-chain 这些业务落地能力。后续升级时,冲突面主要集中在少量注入块,而不是整套 Trellis 内核。
6. skill-garden 0.6 强化包介绍
skill-garden 是本站作者维护的 Trellis 强化补充包。它不是官方 Trellis 的替代品,而是在官方 workflow 上补一组更贴近日常业务开发的技能,尤其适合“需求文档 → 任务三件套 → 实现检查 → 全链路验证 → 提交记录”的闭环。
0.6 版本会读取目标项目的 .trellis/.version。当版本为 >= 0.6.0,包括 0.6.0-beta.x 时,安装 .trellis/0.6/ 变体:精简为 9 个核心 skill,全部 skill 化,不再维护旧的 commands 目录。
按完整链路理解 0.6 核心技能
| 链路阶段 | 技能 | 定位 | 使用时机 |
|---|---|---|---|
| 需求文档转换 / 版本拆分 | trellis-plan-version |
需求文档转版本开发计划、任务拆分、工时评估和分工 | 新版本启动时,先把需求总表变成可执行版本计划 |
| 根据产物生成 PRD | trellis-extract-prd |
从正式需求文档严格提取单个需求的 PRD + task.json,不自由发挥 | 版本计划拆出单任务后,生成任务级 PRD |
| PRD 细化 / task check | trellis-verify-task |
校验 prd.md、design.md、implement.md 三件套准确性、覆盖度和跨层一致性 |
三件套完成后、开发前 |
| 实现 / 检查路由 | trellis-route |
进入 implement / check 前选择 inline、subagent、check-all 或轻量 check | Phase 2.1 / 2.2 / 3.1 |
| check impl | trellis-check-all |
PRD 对照、假设验证、规范一致性和实现完整性综合检查 | 开发完成后、提交前 |
| check cross / full chain | trellis-run-full-chain |
按“场景-路径-期望”做 UI、API、DB 跨层验证 | PR 前 UAT 回归或高风险链路验证 |
| commit / push | trellis-push |
多仓 commit / push / 可选 merge,并写入任务进度快照供下次会话恢复 | 代码完成并通过检查后 |
| 流程梳理 / 扩展入口 | trellis-draw-uml、trellis-create-command |
前者用于复杂业务流程图,后者用于继续扩展 Trellis 入口 | 需求很绕或需要扩展自定义技能时 |
这样理解会更贴近第 5 节的魔改链路:先把需求文档变成版本计划,再抽任务 PRD,随后校验三件套、进入实现、做实现检查和跨层验证,最后提交并记录 session。
trellis-route 的注入原理
trellis-route 不是替代 Trellis 官方 workflow,而是在 .trellis/workflow.md 末尾追加一段带 sentinel 标记的 override。因为它追加在官方 workflow-state 之后,所以能在 Phase 2.1 / 2.2 / 3.1 这些关键边界上覆盖默认行为:进入实现或检查前,先让用户选择 inline、subagent、check-all 或轻量 check,再按选择执行。
| 维度 | 说明 |
|---|---|
| 原因 | 不同任务不一定适合同一种执行模式:小文档可 inline,大改动可 subagent;提交前通常应该 check-all,而不是只跑轻量 check。 |
| 效果 | 把“本次实现 / 检查怎么跑”的决策前置到 phase boundary,避免 Agent 直接按默认路径开写或漏掉全面检查。 |
| 升级边界 | 注入块有 sentinel,可以重装、刷新或替换;它不要求改 Trellis 官方脚本,因此比 fork 上游更容易跟随官方版本升级。 |
快速上手:让 AI 代安装
实际使用时,我不会让用户记安装参数,而是直接把这件事交给当前编程工具里的 AI。最短说法就够了:说明要安装 Trellis 强化包,再贴出 skill-garden 仓库链接,剩下让 AI 自己读 README、安装脚本和当前项目的 .trellis/.version。
帮我安装下 Trellis 强化包
https://github.com/SilentFlower/skill-garden手动脚本入口
# 远程一行安装(示例 raw-url 请以仓库 README 为准)
bash <(curl -fsSL <raw-url>/install.sh) \
--repo git@github.com:SilentFlower/skill-garden.git /path/to/project
# 只安装 / 刷新 workflow 增强块
bash skill-garden/scripts/install.sh /path/to/project workflow-enhancement
# 已经 checkout skill-garden 时
bash /path/to/skill-garden/scripts/install.sh \
--repo /path/to/skill-garden /path/to/projecttrellis-extract-prd、trellis-verify-task、trellis-route、trellis-check-all 等是 skill-garden 对 Trellis 的增强层;Trellis 官方能力仍以官方仓库和 changelog 为准。
trellis-push 的 0.6 改动
新版 trellis-push 已经不只是“帮你提交代码”。它会读取 .trellis/config.yaml 里的 packages 多仓配置,对前端、后端等子仓分别检查变更、生成提交、推送当前分支,并可按 packages.<name>.merge_target 合并到测试线。首次缺少 merge_target 时,它会询问目标分支并回写配置。
| 能力 | 说明 |
|---|---|
| 多仓提交 | 按 packages 只处理有变更的 git 子仓,禁止默认 git add -A,每仓暂存前都要展示文件并确认。 |
| 目标分支合并 | 推送当前任务分支后,可选择合并到 test 等目标分支;目标分支可记录在 merge_target。 |
| 任务进度快照 | 读取当前任务的 implement.md、base_branch 和本次 pushed commits,写入 task.json.last_push_snapshot。 |
| 跨会话恢复 | 快照写入后会额外提交并推送 harness 父仓。下次新会话没有 active task 时,workflow guard 可提示“上次 push 做到哪一步、下一步是什么”。 |
7. skill-garden 强化包开发流程与经验
强化版流程的重点是把“需求处理”和“质量门禁”前移。原版 Trellis 可以从自然语言进入 PRD;skill-garden 0.6 更适合有正式需求文档的团队,把需求提取、任务校验、路由、全量检查和全链路验证都变成明确技能。
需求文档
→ trellis-plan-version # 版本计划、需求拆分、工时评估
→ trellis-extract-prd # 单任务 PRD + task.json 严格提取
→ prd.md / design.md / implement.md 细化
→ trellis-verify-task # 三件套校验
→ 启动 gate / workflow 切到 in_progress
→ trellis-route(implement) # inline 或 subagent
→ trellis-route(check)
→ trellis-check-all # 提交前综合检查
→ trellis-run-full-chain # 关键场景跨层验证
→ trellis-push # 多仓提交 + merge target + last_push_snapshot
→ finish-work / record session我的使用建议
- 版本级任务先用
trellis-plan-version:先把需求总表变成版本计划,不要一上来就让 Agent 逐条实现。 - PRD 生成要区分 extract 和 brainstorm:有正式需求文档时用
trellis-extract-prd严格提取;需求还不清楚时才用 Trellis 官方的trellis-brainstorm对话澄清。 - 实现前必须跑
trellis-verify-task:PRD、设计、实施计划如果互相矛盾,后面的实现越快,返工越大。 - 提交前优先
check-all:普通 lint/typecheck 只能证明代码能跑,不能证明实现覆盖了需求。 - 跨层场景单独列表:涉及 UI、API、DB、外部系统时,用“场景-路径-期望”表驱动
trellis-run-full-chain,不要把它混同为前端 e2e。
8. Trellis 落地实践:IQS 系统版本开发
/root/project/human 里最能说明 Trellis 价值的不是单个页面改动,而是 IQS v1.3.0 在 2026-04-23 到 2026-04-27 这一轮真实冲刺:一个版本里同时存在状态机、导入导出模板、前后端字段透传、审批回调、列表筛选、详情抽屉和稳定性修复。Trellis 的作用是把这些散射需求拆成可追踪任务,再让每个任务沿着 PRD、实现、检查、修复、记录往前推进。
v1.3 版本级输入
| 素材 | 作用 |
|---|---|
doc/SRM-IQSv1.3.0需求文档.md |
版本主需求文档,包含状态机、列表、详情、导入导出、审批和验收规则。 |
doc/需求列表_v1.3.0.csvdoc/v1.3.0-需求清单.md |
把需求总表和全文扫描对齐:25 条需求中 7 条已完成排除,18 条待开发纳入计划。 |
doc/v1.3.0-开发计划-工时评估.md |
按 1 人全栈 + AI 辅助模式排期,拆出 P0/P1/P2、散射主题、每日计划、风险和 QA 回归窗口。 |
计划拆分方式
v1.3 不是简单按菜单拆,而是先把 18 条待开发需求分成 4 条 P0、10 条 P1、4 条 P2,再识别 5 个跨模块散射主题。这样做的好处是:同一个字段文案、同一个状态名、同一套模板、同一个部门快照字段不会被拆到多个任务里各写各的。
| 规划维度 | v1.3 处理方式 | Trellis 价值 |
|---|---|---|
| 需求边界 | 25 条扫描结果中排除 7 条已完成,剩余 18 条进入本轮计划。 | 避免 Agent 把已上线需求重复实现,或把游离需求漏掉。 |
| 优先级 | P0 4 条、P1 10 条、P2 4 条,先做状态机、模板、批量关闭、转手、报价等高风险链路。 | 先把版本节奏锁住,再创建 Trellis task。 |
| 散射主题 | S1 字段文案、S2 已驳回状态、S3 执行员部门快照、S4 分标分包字段、S5 任务模板一体化。 | 把跨页面、跨接口、跨模板的变更合并思考,减少只改一处的漏实现。 |
| 工时口径 | 计划按 1 人全栈 + AI 辅助估算,汇总约 43.5h 开发与自测,另留 QA 回归窗口。 | 让任务拆分服务于真实排期,而不是只服务于文档好看。 |
| 仓库边界 | 前端在 iqs-front-human,后端在 iqs,harness 根层统一保存需求、任务和 session。 |
一个任务可以同时约束前端、后端、文档和验证,但不打乱业务仓库自身发布节奏。 |
4/23-4/27 的代表任务批次
| 时间 | Trellis 任务 | 实际处理 |
|---|---|---|
| 04-23 | 04-23-disp-009-batch-close-adjust |
在第一版批量关闭基础上接真实审批流程、修正明细 JSON key、兼容审批实例号,并把跨项目拆单改为同项目强校验。 |
| 04-23 | 04-22-08-task-dtl-003-quote-unlock04-22-10-task-list-list-enhance |
推进报价字段解锁、型号搜索、采购任务列表筛选、Tab、展示列和组内权限,前后端同步改。 |
| 04-24 | 04-22-11-proj-dtl-001-display-enhance04-22-12-task-dtl-001-drawer-optimize04-22-14-proj-dtl-002-edit-enhance |
集中处理项目详情展示、任务详情抽屉体验、项目详情编辑态字段控件,避免详情页多个状态互相打架。 |
| 04-25 | 04-25-task-import-brand-display-order |
补导入模板中的品牌展示顺序问题。这个任务很小,但能说明模板类需求不能只看主流程,Excel 细节也是验收点。 |
| 04-27 | 04-27-srm-iqs-v130-gap-fixes |
对照 v1.3 原文做漏实现审计,补字段文案、秒级时间、资料要求“产品物料编码”映射、临时物料时间轴跳转。 |
| 04-27 | 04-27-fix-attachment-zip-stuck-on-restart |
处理异步附件打包在服务重启或超时后卡住的问题,补启动恢复、超时兜底、多实例隔离和后端 spec。 |
| 04-27 | 04-27-fix-task-list-assignee-filter-text-revert04-27-fix-rejected-task-quote-lock04-27-fix-single-task-batch-close-payload |
集中收尾筛选兼容、已驳回任务报价锁定、单任务批量关闭参数等回归问题,把 QA 反馈继续变成小 Trellis 任务。 |
单任务怎么落地
- 先锁任务边界:每个任务只吃自己负责的 REQ 编号和来源位置,PRD 明确“不做什么”,避免一个任务越改越大。
- 复杂任务写三件套:批量关闭、模板重构、异步任务恢复这类跨层任务,必须有
prd.md、design.md、implement.md,否则后面很难判断实现是否偏航。 - 前后端作为 packages 协同:同一个任务可以同时改
iqs-front-human和iqs,但提交、分支、merge target 仍按子仓独立处理。 - 缺口修复也任务化:04-27 的漏实现修复不是随手补代码,而是先把审计结论写成 PRD,再逐项覆盖 AC。
- 经验反哺 spec:异步任务恢复、多实例隔离、导入模板兼容这类踩坑点,适合写回
.trellis/spec,让后续任务自动继承。
后续演进:v1.4 的计划化拆分
v1.3 之后,IQS v1.4 已经把这种方式继续前移:先从 v1.4 原始需求文档生成需求清单和开发计划,再把 P0 范围拆成 5 个 planning 任务,例如项目侧基础与编辑闭环、图片与附件导入导出、任务报价流、分派/SRM 流程、考核报表。区别在于 v1.3 更像“边冲刺边修正”,v1.4 已经更接近“版本计划先行,再进入任务三件套”。
OpenSpec — 规范驱动开发框架
1.3.1(2026-04-21 发布),OpenSpec 仍在快速迭代,命令、profile 和支持工具可能继续变化;正式使用前请以 官方仓库、命令文档 和 npm 包页 为准。
OpenSpec 是什么
OpenSpec 是一个面向 AI Coding Assistant 的开源 Spec-Driven Development(SDD)工具。它把“想让 AI 做什么”沉淀成 proposal.md、Delta Spec、design.md 和 tasks.md,再让 AI 按这些 artifacts 实现,而不是只依赖一段聊天上下文。
核心定位:OpenSpec 是跨 AI 编程工具的轻量规格层,用 Markdown artifacts 把需求、设计、任务和归档历史串起来。
| 项目 | Fission-AI/OpenSpec |
| 开源协议 | MIT |
| GitHub Stars | 约 4.5 万+(高频变化数据,以 GitHub 为准) |
| 支持平台 | 25+ AI coding assistants(Claude Code、Codex、Cursor、Gemini CLI、GitHub Copilot、Kiro、RooCode、Windsurf 等) |
| 运行要求 | Node.js 20.19.0+,CLI 包名 @fission-ai/openspec |
| 安装方式 | npm install -g @fission-ai/openspec@latest |
快速开始
安装并确认版本
npm install -g @fission-ai/openspec@latest
openspec --versionOpenSpec 需要 Node.js 20.19.0 或更高版本。也可以使用 pnpm、yarn、bun 或 Nix 安装;为了减少环境差异,建议优先使用官方最常见的 npm 命令。
初始化项目
# 交互式初始化
openspec init
# 也可以显式指定工具,减少初始化选择步骤
openspec init --tools codex,claude,cursor初始化后,项目根目录会出现 openspec/ 目录。主规格放在 specs/,待实现变更放在 changes/。
openspec/
├── specs/
│ └── <domain>/
│ └── spec.md
├── changes/
│ └── <change-name>/
│ ├── proposal.md
│ ├── design.md
│ ├── tasks.md
│ └── specs/
│ └── <domain>/
│ └── spec.md
└── config.yaml让 AI 生成项目上下文
请阅读当前项目的 README、目录结构和核心代码,帮我补全 openspec/config.yaml。
重点写入:
- 项目用途
- 技术栈
- 运行方式
- 目录结构
- 编码约束
- 不希望引入的复杂度
- proposal/specs/design/tasks 的生成规则这一步更适合让 AI 先扫项目并生成初稿,再由人 review、删减和纠偏。config.yaml 是长期上下文,不应该把某一次具体需求写进去。
# AI 生成并经人工审阅后的 openspec/config.yaml
schema: spec-driven
context: |
项目:天气卡片示例项目。
技术栈:原生 HTML、CSS、JavaScript,无构建工具。
运行方式:直接打开 index.html,或使用静态文件服务器。
数据来源:本地静态天气数据,不接入真实天气 API。
约束:
- 不引入 React、Vue、Vite 等框架。
- 不需要 npm install。
- 所有文案使用中文。
- 天气卡片需要兼容桌面和移动端窄屏。
rules:
proposal:
- 明确说明本次变更为什么需要做。
- 明确哪些内容不在本次范围内。
specs:
- 使用 ADDED / MODIFIED / REMOVED 描述增量规格。
- Scenario 使用 Given / When / Then 格式。
design:
- 说明数据结构、DOM 渲染方式和响应式布局方案。
tasks:
- 任务按数据、界面、交互、验证拆分。某次具体需求应该进入 openspec/changes/<change-name>/。例如“增加 3 天预报”属于 change,不属于 config.yaml。
更新工具指令
openspec update修改 config.yaml、升级 OpenSpec 包或调整 profile 后,建议运行 openspec update,把最新 agent instructions 写入当前工具。不同工具的触发形式略有差异,以初始化后生成的命令或 skill 名称为准。
先探索项目,再创建变更
/opsx:explore 请阅读当前项目,梳理已有功能、目录结构、技术栈和适合用 OpenSpec 管理的改动点/opsx:explore 不创建 artifacts,适合先读代码、澄清需求、比较方案。思路清楚后,再用 /opsx:propose 创建具体变更。
默认工作流
OpenSpec 官方更强调“动作”而不是僵硬阶段。默认 core profile 的最常用路径是:
/opsx:explore → /opsx:propose → /opsx:apply → /opsx:sync → /opsx:archiveExplore:先理解项目和问题
/opsx:explore 用来在创建 change 之前调查问题、阅读代码、澄清需求和比较方案。它不会创建 proposal.md、spec、design 或 tasks;当方向明确后,再进入 /opsx:propose。
Propose:把想法变成 artifacts
使用 /opsx:propose "你的想法" 创建变更目录,生成 proposal.md、Delta Spec、design.md 和 tasks.md。这一步回答“为什么做、做什么、怎么验收”。
Apply:让 AI 按任务清单实现
使用 /opsx:apply 后,AI 会读取 OpenSpec artifacts,按 tasks.md 逐项实现并更新任务状态。这里的关键是:AI 不是直接改代码,而是被 spec 和 task 约束。
Sync / Archive:把变更沉淀为长期规格
/opsx:sync 会把 delta specs 合入主 specs;/opsx:archive 会检查完成情况,并把已完成变更移入 openspec/changes/archive/,保留 proposal、design、tasks 作为审计历史。
/opsx:verify、/opsx:onboard、/opsx:bulk-archive 等不属于默认 core profile。需要这些命令时,先运行 openspec config profile 选择 expanded/custom workflow,再运行 openspec update。
完整例子:天气卡片
仓库里新增了一个可直接打开的示例项目:example/weather-card/。下面是一条端到端 OpenSpec 使用路径:从一个简单天气卡片开始,生成 proposal、Delta Spec、design 和 tasks,再完成查看、校验、实现、同步和归档。
打开示例项目并初始化 OpenSpec
cd example/weather-card
npm install -g @fission-ai/openspec@latest
openspec --version
openspec init --tools codex,claude,cursor
openspec update这一步先让天气卡片项目有 openspec/ 目录和当前 AI 工具可用的 OpenSpec 指令。初始化后让 AI 阅读项目并补全 openspec/config.yaml,再人工审阅和精简。
探索现有项目
/opsx:explore 请阅读当前天气卡片项目,梳理已有功能、文件结构、技术栈和适合用 OpenSpec 管理的改动点这一步先让 AI 理解当前天气卡片,而不是马上生成变更 artifacts。探索完成后,再选择一个具体改动进入 propose。
创建变更提案
/opsx:propose add-forecast-city-switcher可以把需求直接写给 AI:给天气卡片增加 3 天预报,并允许用户在北京、上海、广州之间切换城市。OpenSpec 会把这句话拆成可审阅的 artifacts。
查看生成产物
openspec list
openspec show add-forecast-city-switcher
openspec validate add-forecast-city-switcheropenspec/changes/add-forecast-city-switcher/
├── proposal.md
├── design.md
├── tasks.md
└── specs/
└── weather-card/
└── spec.mdproposal.md 说明为什么改,spec.md 写可验证行为,design.md 说明实现方案,tasks.md 是 AI 后续编码清单。
理解 Delta Spec
## ADDED Requirements
### Requirement: 3 天天气预报
天气卡片 MUST 展示所选城市未来 3 天的日期、天气状态和最高/最低温度。
#### Scenario: 查看北京未来 3 天天气
- GIVEN 用户打开天气卡片
- WHEN 默认城市为北京
- THEN 页面展示北京未来 3 天预报
- AND 每一天都包含日期、天气状态、最高温和最低温
### Requirement: 城市切换
天气卡片 MUST 支持在北京、上海、广州之间切换,并同步更新当前天气和 3 天预报。Delta 只描述本次新增能力,可以直观看到“需求如何变成可测试行为”。
实现、校验、归档
/opsx:apply add-forecast-city-switcher
openspec validate add-forecast-city-switcher
/opsx:sync add-forecast-city-switcher
/opsx:archive add-forecast-city-switcher如果已经启用 expanded/custom workflow,可以补充使用 /opsx:verify add-forecast-city-switcher;如果没有启用,使用 openspec validate 做结构校验即可。
openspec/specs/weather-card/spec.md,本次变更移动到 openspec/changes/archive/,proposal / design / tasks 变成可追溯历史。
/opsx:apply 会受模型、环境和测试耗时影响。可以提前准备好 change 目录,重点查看 propose、artifact 结构、validate 和 archive。
真实项目实践:从示例到业务系统
天气卡片适合演示 OpenSpec 的最小闭环;真实项目里,OpenSpec 更大的价值是把复杂业务规则、跨模块影响和实现步骤提前沉淀成可审阅 artifacts。
srm-boot:存量 SRM 系统的规格沉淀
/root/project/srm-boot 已经包含主规格、进行中变更和归档变更,覆盖 SCP 发运、落地合同、付款校验、SAP/FICO、供应商权限同步、TextIn 验收抽取等场景。它更适合说明 OpenSpec 如何在 Java 8、Spring Boot、多模块存量系统里沉淀业务规则,并把完成后的 Delta Spec 合入长期规格。
human/iqs:进行中需求的并行拆解
/root/project/human/iqs 的 OpenSpec 实践更偏向进行中的业务迭代,包含询价项目、任务分派、报价协同、SRM/MPM/飞搭回调、OpenAPI 文档补齐和筛选条件一致性等变更。它适合说明 OpenSpec 如何把多个并行需求拆成 proposal、design、tasks 和 Delta Spec,让 AI 编码前先对齐边界、数据流和验收点。
常用命令
默认 core profile 命令
| 命令 | 功能 | 使用时机 |
|---|---|---|
/opsx:propose |
创建变更提案 | 有新需求/改动时 |
/opsx:explore |
探索需求或代码上下文 | 需求不清楚、需要先调查时 |
/opsx:apply |
按 Spec 实现任务 | 开始编码时 |
/opsx:sync |
同步 Delta Spec 到主 Spec | 实现完成、准备沉淀规格时 |
/opsx:archive |
归档已完成变更 | 任务完成后清理 active changes |
expanded/custom workflow 命令
以下命令不是默认 core profile 的固定内容。需要先运行 openspec config profile 选择 expanded/custom workflow,再执行 openspec update。
| 命令 | 功能 | 使用时机 |
|---|---|---|
/opsx:new |
创建更结构化的新变更 | 团队希望更明确区分 proposal 创建动作时 |
/opsx:continue |
继续未完成的变更 | 中断后恢复上下文 |
/opsx:ff |
快速推进已准备好的变更 | proposal / tasks 已清楚,想减少来回确认时 |
/opsx:verify |
检查实现与 artifacts 的一致性 | 编码完成后做 completeness / correctness / coherence 检查 |
/opsx:onboard |
新成员快速上手 | 新人加入、需要快速理解 specs 和 changes 时 |
/opsx:bulk-archive |
批量归档 | 清理积压变更 |
CLI 辅助命令
| 命令 | 功能 | 价值点 |
|---|---|---|
openspec list |
列出当前 specs / changes | 快速确认当前有哪些活跃变更 |
openspec show <change> |
查看某个变更详情 | 查看 proposal、spec、design、tasks 的组合视图 |
openspec validate <change> |
校验变更结构和规格格式 | 最稳定的结构检查动作 |
openspec validate --all --json |
以 JSON 方式校验所有 specs / changes | 适合接入 CI 或脚本化检查 |
openspec update |
刷新当前项目里的 agent instructions | 升级包或切换 profile 后必须强调 |
适合场景
| 场景 | 推荐度 | 说明 |
|---|---|---|
| 已有项目迭代开发 | ⭐⭐⭐⭐⭐ | Delta Spec 只描述本次增量,适合在已有系统上持续演进 |
| 多工具切换使用 | ⭐⭐⭐⭐⭐ | 25+ AI coding assistants 支持,同一套 specs / changes 可跨工具延续 |
| 需要轻量级规范管理 | ⭐⭐⭐⭐⭐ | 用 Markdown artifacts 管理需求、设计、任务和历史,不需要引入复杂平台 |
| 新项目从零开始 | ⭐⭐⭐ | 可用,但它的优势更偏向持续迭代中的规格沉淀 |
| 需要完整工程编排 | ⭐⭐ | OpenSpec 专注规格和变更 artifacts,不负责工作树隔离、并行 Agent 调度或团队任务系统 |
内容结构
定位
OpenSpec 不是“又一个 AI 编辑器”,而是放在不同 AI 编程工具之上的规格层。它把需求、设计、任务和历史变成项目内可追踪的 Markdown artifacts。
默认路径
core profile 的主线是 propose、apply、sync、archive。expanded/custom 命令用于补充更完整的工作流。
核心产物
关键不只是输入斜杠命令,而是 proposal.md、spec.md、design.md、tasks.md 这些 artifacts 如何约束 AI 编码。
边界
OpenSpec 管规格和变更闭环,不负责完整项目管理、并行 Agent 调度或生产环境发布。它最强的点是让 AI 编码前后都有可审阅、可归档的依据。